

Pythonで学ぶデーダ処理の初歩 (2008-01-08 版)
ここではプログラム言語Pythonを使ってデータ処理をする方法を簡単に提示する.
2006年九月二日 地質調査船 白嶺丸に於いて起筆.
近年は計算機資源が安価になり, 多くの一般の人もパソコンを購入し, 計算機に
触れるようになった. それによって, コンピュータユーザは増えたが, 計算機の
基礎教育を学んだ人が増えたわけではない. そして, 計算機の利用は高まった結
果, 計算機の基礎教育を学んでいない人でも重要なシステムの運用や管理をしな
ければいけなくなっている. コンピュータビギナーであるかシステムマネジャー
であるかに関わらず, 少しコンピュータを使い込むといつか必ず衝き当たる壁が
ある. 市販や既存のソフトウェアでは, 自分のしたいことが実現できない
という壁である. この時, 人は別れ道に立たされる. 未来永劫, 市販・
既存のソフトウェアに,自分ができることを規定される立場に甘受して暮すのか,
それとも, 計算機技術を学び自分でやりたいことを実現する能力を身につ
けるのか. 私は人間の自由と主体性を重んじるので,自分でやりたいことを実
現する能力を身につけることを強く勧める.
本書が読者の自由に貢献することができれば幸いである. 次に, 読者の中になぜ
Pythonかという疑問が生じるかもしれない. 私はPythonでなければプログラムで
はない, などというつもりはない. むしろその逆である. プログラムは特定の言
語(Java, C...)でなくとも, プログラム言語であれば使えるし学ぶ対象になる.
Python以外にもデータ処理をする方法はある. ざっと思いつくだけでも, (1)
Shell Script + Awk, (2) Perl, (3) MS-Excel, (4) C, (5) Java, (6)
Fortran, (7) Python とある. それぞれの利点と弱点を考察してみよう.
(Ruby, Lispなども当然,評価すべきであるが私の能力を越えるため割愛する)
ちなみに,MS-Excel以外は全てフリーウェアである.
Shell Script + Awkは伝統的なUnix使い向けの方法であり, unix userにとっ
て必須のスキルである. コマンドを組みあわせてデータ処理する技法はデータ
処理の基本的な考え方を教えてくれる. プログラム言語といってもよいが, 変
則的なワザを組みあわせて, データを処理することが多いので, 最初にデータ
処理を学ぶにはおすすめできない(最初にUnixを学ぶにはお勧め/というより必
須であるが) . Unixを使うのであれば, そのうち使う. Unixのシェルの取扱
いについてはArthur and Burns (1997); Kernighan and Pike (1984); 砂原他 (2001,1996)等を,Awkについては
Dougherty and Robbins (1997); Aho et al. (1989)を参考にされたし.
Perlは(1)を置換できる機能をもつスクリプト型プログラム言語である. 非常の
高機能でモジュールも多く, 主要なモジュールはCPANというサイトに登録されて
おり, 世界中から自由に利用参照できる. しかもユーザー数が多く, 教科書も優
れたものが多い. 言語は比較的自由に記述でき, 「一つのことをするのに複数の
方法がある」ことを目標としており, ある機能を実現するのに, 何通りかの方法
で書けるようになっている. 弱点としては再利用可能性・可読性の低さがある.
再利用可能性の低さはプログラムの自由度の高さと関係している. 機能の切り
分けができていないモジュールは計算機上では問題がなくても, プログラムの仕
様を人間が理解できないため再利用できないものになりがちである. また, Perl
では記号(例 $_)に特殊な意味を割当てているので,
プログラムが宇宙人語風になりがちである(例
$_.='@'|'*'&~'!';).
そのため, しばらく使っていないと忘れてしまう.
同じことを何通りでも書けるのもよしわるしで, 如何様にでも書けるため, 気分
によってコードの体裁がばらばらになってしまい, 読みにくいコードになる. こ
のような理由で, プログラムを書きはじめの人や, 散発的に改変する人には向か
ない言語と思っている. とはいえ unix user必須の技術であることには違いない.
入門書としては,斎藤他 (1996); 深沢 (1999); Schwartz and Christiansen (1997)がある.とくに
Schwartzのものはラクダ本と呼ばれて親しまれている.ただし本当のラクダ本は
Programming Perl(Wall et al., 2000)である.Pythonとの比較にはBrowm (2002)
がある.
MS-Excel は組織化されていないビジネスユーズで最も広範囲に用いられている
表計算ソフトである1.1. MS-Excelは作表の機能は完全に満しているが, データ処理の
ツールとしては致命的な欠点があるため, Excelはデータ処理の王道にはなりえ
ない(と私は診断している). Excelでデータ処理を修得すると間違った習慣が身
につく恐れがある.主な欠点は次の通りである.Excelのワークシートはデータ
構造をなんでも二次元の配列(表)にしてしまい, データの本来もっている論理構
造を反映しない形でしか扱えない. たとえば表のタイトルは一番上に掲示される.
Excelで云うと一行目の最初の列A1にタイトルが記入される.データ構造は一行
あけて3行目くらいから始まる.しかし最初の行は項目の説明に費やされるので,
データ本体は4行目からである.論理的になんの関係もないものが,1〜4行目ま
で並列に取り扱われてしまうのである.しかも表のタイトルは人によって表の真
中くらいの列でD1くらいに記入されることもある.まったく見て呉れだけで論理
的ではない.端的にいってしまえばExcelは計算のために存在するのではなくて,
レイアウトを指定するために存在しているのかもしれない(とはいえ,列幅の異
なる複数の表を同じシートでは取り扱えないという欠点がある).
人間とは融通が効くものでデータ構造がおかしなものを見せられても, 「ああ,
これはこういうつもりなんだけど, 表にはうまく書けないので, このセルに入れ
たのね」と好意的に解釈してくれることが多い.しかし, 好意的な解釈は「常に」
ではない. また, データ構造のおかしなものばかりを見ていて, 構造のおかしさ
に慣れてしまったり, 構造のおかしなところを修正できないので人間のほうで
合せるのが通常になると, その人の論理的なデータ処理能力も衰退する. なんで
もかんでも二次元のデータシートに押し込む考え方に欠点がある.次の欠点とし
て,入力系と出力系が整理されていないことがある.人からExcelのファイルを
もらった時に,どこに入力して,どこに結果が返ってくるのか,作った人に解説
してもらうか,自分でセルを隈なく調べないとよくわからない.多少なりともシ
ステム化された体制をもつ動物は口と尻(肛門)が決まっていて,どこから入力さ
れて,どこから出力するかは定まっている.アメーバのような単純な動物はそう
ではなく,どっからでも出し入れができるようになっている.入出力の場所がちゃ
んと決まっていないExcelはアメーバのように未分化なシステムである.特に,
中間的な計算結果がずいぶんと遠くのセルに置いておかれることもあって,セル
の中の函数をいちいち追跡していかなければいけない.プログラムは文章と同じ
で一次元だから,最初から読んでいけばよい.しかしシートは二次元なので順番
に,というわけにはいかない.
また, Excelではインタラクティブ(人が計算機の前に座って, 処理が済むごとに
逐一指示を出すこと)でないと処理できない. これは, 計算機に処理の指示書を
書いて, 自分は他のこと(家にかえって寝る, ネコと遊ぶ等)をできないことを意
味している. 計算機の前で, 数分待たされては処理が済み, また次の処理をマウ
スでクリックして数分待つということを繰り返すことを意味している. これでは
データ処理を自動化できない. 今回例にあげた他の候補は全て, 処理を自動化で
きる. VBを使えば自動化はできるが, VBは使いやすくもないし, 設計がきれいで
もないし, robust(堅牢)でもない. VBのセキュリティの脆弱性はよく知られたと
ころである. このような理由からExcelはデータ処理の主力兵器としては向かな
いと云える. どうしても使いたい向きはHawley and Hawley (2004)を参照されるとよい.
補足 Visual Basic:Visual Basicはプログラム言語であるがお薦めしない.理
由についてはRaymond (2005)を参照されたい.
Cはunix hackerのmother tougue(母語)といわれている. 文法的規則が少なく,
かなり自由度の高い言語である. ハードウェアの基本的なところを制御できる強
力な言語であり, ユーザーも多い. ただし, 修得は難しく, データ処理用にアレ
ンヂするには「基礎学力」が必要である. その「基礎学力」のレベルが高い. C
を理解するには, ハードウェアの原理や計算機の中でどうしてプログラムを走っ
ているのか深い理解をする必要があり, 初学者にそれを求めるのは難しいし, デー
タ処理のユーザーには当面必要のない知識である. JavaはSunが開発したobject
指向のプログラム言語で, 一時ブームになり, 多くのユーザーが存在する. 多く
のプラットフォームでそのままコードが動くのが特徴である. Once write, run
everywhere. ただし, 最近では MicrosoftがWindowsでしか動かないJavaの拡張
を提案しており, 互換性の高さもいつまで続くのか不安がある. データ処理の実
務者としては, 人からもらったJavaのcodeがちゃんと動くのかどうか気になると
ころである. JavaはCほどベーシックではないが, いろいろなことができるよう
になっており高機能であるものの, データ処理用に特化していないため, Javaで
データ処理をするには, それなりの「基礎学力」が必要である. Javaはきちんと
したCのコードがかける能力がないと, Perlのように可読性・再利用性に劣るコー
ドを生産してしまいがちである. このように, CやJavaは高機能であるため, 逆
にデータ処理の実務者の初学には適さないと考える.
C言語は1972年誕生の古い言語で(もっと古いのもあるが),いろいろなレベルの
本が用意されている.もっとも代表的な参考書はKernighan and Ritchie (1988)があり,K&R
本と呼ばれている.出版社はこの本が大量に売れることを期待していなかったが
5000万部以上売れた著名な本である.ただし,この本は初学者には非常に閾が高
い.C言語には非常に多くの参考書があるが,初学者のよい学習書として
結城 (1995,1998)がある.よりコンサイスな入門書には
椋田 (1993)がある.C言語の言語構造のヒントをまとめたものに
アンク (2002)がある.Javaについては結城 (1999a,b)を参照された
い.
Fortranは1980年代ごろから科学技術計算のために開発された言語で, データ処
理を目的としている. ただし, 現在ではユーザーは少ないように思う. また,
言語の設計が古いため, 現在のデータ処理に若干不向きなところがある. たとえ
ば,C言語のように記述に自由度の高い言語だと, データ処理の内容にあわせて
自分でコードを書くので現状にあっていないところも気にならないのだが,
Fortranは科学技術計算に特化しているため,現在の状況にあっていないところを
修正するのは面倒になると思われる. 量子力学や素粒子物理学,宇宙論では過去
の遺産として膨大なFortranプログラムが存在し,遺産を継承する形で現在も使
われつづけている.おそらくこの分野においては将来も継続するものと思われる.
言語の詳細は調査中である. 教科書には原田 (1986)がある.
Pythonはperlの高機能をもち, 可読性が高いのを特徴とする. 手続き式でも
objectiveでもコーディングできる. コーディングスタイルとしてプログラムの
論理構造を反映させたコードの構造にしないといけないので, 自然と論理的で読
みやすいコードになる利点がある. Perlが一つのことをするのに複数の方法をで
きるようにしているのに対して, Pythonは一つのことをするには一つの方法で実
現できるように設計されている. そのため, 記述が気分によってかわったりしな
い. また, 指示子に記号を使うことを極力避け, 関数やオブジェクトは一見して
理解できる名前になっており, あとから(しばらく時間があいて忘れかけた頃に)
読んでも, なにが書いてあるか容易に理解できる. Pythonのユーザー層には相当
のscientistがおり, 科学技術コミュニティおよびモジュールのが充実している.
膨大にあるCも関数やFortranのモジュールも簡単に外部関数として参照できるよ
うになっており, 将来ハイレベルのデータ処理をする時にも人の関数・ライブラ
リを参照できるし, また, 計算速度を求められる重要な演算の部分だけをCで書
いて, Pythonからそれを参照するように使うこともできる. 全体のコードの流れ
をPythonで書くことで見易くなり, 律速的な計算をCで書くことで速度もはやく
することができる. このように初学者には利点の多い言語であり, 今回紹介し
たい. 唯一の欠点は, 動作速度が(1)-(7)[Excel除く]の中で最も遅いことで,
実行速度はPerlの数倍から数十倍遅い(演算内容によっても異なる). ちなみにもっ
とも早いのはCであり, CをPerlとの間も数倍から数十倍の速度の差がある. なお,
Perlでは型は非明示であるが, Pythonでは型は明示である. 型は非明示のほうが
ちょっとしたことをやらせるのは簡単だが, 本格的なコードを書くと型はあいま
いなので, プログラマーのほうで頭の中で型を把握しておかなければいけないた
めかえって管理コストが圧迫する(つまりデバッグやレビューが困難になる).
Pythonの参考書についてはあとでまとめて記述する.
結局のところ決め方は, 近くにいるプログラム言語を知っていて人柄の印象がよ
い人(これ重要)が勧めるものを使うというがもっとも妥当な決め方のようだ.
というのは, 一人でやっていてつまずいた時(かならずつまずく, 最初から全て
うまく行く人はいない), 本を読んでもわからず(本を読んでわかるというのは,
自分がなにをわかっていないのはわかっているということ. 初学者はたいてい何
をわかっていないもわからないものである), 頼れるものは究極的には近くの人
である. 私個人としては, Excel以外のどの言語であっても(Excelはそもそも言
語ではない), 適格なアドバイザーの近くで学ぶなら, どれでもいいと考える.
言語には固執する価値はないが,教える者の人柄は重要である.理解というのは
究極的には理解する側の問題である.教える側にできることは限られている.そ
の限られた「できること」は,必要なことを云うこと,不要なことを云わないこ
と,そして,相手を聞く気にさせることである.
人柄の悪さが何にも勝して効率を低下させる (Weinberg, 1979)
また, 私の上述の評説も他の誰かの言語の評説も, なんの言語も知らない人にが
読んでも理解できない. 初学者のための言語の解説も, 言語をある程度知ってい
て解説が理解できる. しかし, 初学者のための言語の解説は言語を知らない人の
ために書かれている. 「運転免許を取るためにはクルマを運転しなければいけな
いが, クルマを運転するには運転免許が必要」というargumentのように, これじゃ
最初がはじめられない(から先に続かない)ということなりかねないが, 人間は最
初がわからないからといってその先もわからないわけではなくて, やっているう
ちにわかってくるということがある. 最初は難しいことばかりだが, 物事の最初
というのは往々にしてそういうものだと思って, 付き合ってあげてほしい.
Pythonはチュートリアルやレファレンス等のドキュメントが充実している.実際,
チュートリアルはそれらへんの入門書と同じくらいの出来栄えである.(しかし,
Python使いがもっともよく使うのは, Library referenceだ.私がプリントアウ
トした時で800頁にもなった.今はさらに増えているだろう...)
http://www.python.jp/Zope/
http://www.python.jp/Zope/links/python_documents
プログラム言語は言語の一つである. 言語は自然言語と形式言語にわけられる.
自然言語は人間がしゃべる言語である. 形式言語は, 数学と論理学とプログラム
言語が含まれる. 自然言語は人間誰でもひとつはしゃべっている. プログラム言
語も自然言語と同じ言語であるから, そういう意味では誰しもプログラム言語に
対する予備知識はあるといえる. プログラマに必要な要件としてはの第一は自然
言語を使えるということである. ただし, 自然言語の一つが使えるからといって
形式言語が使えることにはならない. それは自然言語の一つの英語がしゃべれる
からといって日本語がしゃべれることにはならないのと同様である. だから, 要
件の第二番目以降は, 形式言語と自然言語の違いに起因するものである. 形式言
語では厳密な定義があり, 意味が明確な文からなるのに対して, 自然言語は曖昧
で, しばしば裏の意味があり, 文意が一意に定まらないことがある. たとえば京
都の「ぶぶ漬け食べていってください」=「はよ帰ってください」は有名である.
京都人は, この文は退去の催促という一つの意味しかもたないので明確だと主張
するかもしれないが, 京都人を知らない人には日本人であっても通じない, のみ
ならず誤解を与える. こういう文は明確とはいえない. 形式言語は違う. 形式言
語は「わかる(意味のある文」か「わからない(意味のない文」の二種類しかない.
であるから, プログラム言語を上手く使うためには, 言葉を厳密にかつ平明に使
うことが要件となる. また, 自然言語では, 文脈や飛躍が許されるが, 形式言語
では論理学数学に代表されるように文脈や飛躍は認められない(というか通じな
い). 計算機は数学や論理学の教師よりも融通が効かない. つまり論理的な思考
が要件となる.
しかし, もっとも重要な要件は, 好奇心が強いことである. 好奇心の強さがなに
よりの強い味方となるであろう.
Pythonには,主要なUnix, Linuxシステム用のバイナリーの他,Windowsや
Macintoshのバイナリーも既に存在している(下記url参照).もちろんソースファ
イルも公開されているから,自分で構築(ビルド)することもできる.MacOS Xで
あれば最初からバイナリーがインストール済みで,Linuxディストリビューショ
ンの多くも最初からインストール済みである.NetBSD, FreeBSDなどのBerkeley
は余分になり得るものを極力排除する設計思想のために,最初からはインストー
ルされていない.しかし,pkgsrc/portシステムによりソースファイルから簡便
にビルド・インストールできるし,サイトにはバイナリーファイルも用意されて
いる.個人的にはソースから自分が使う仕様を調整してビルドするのが好きであ
るが,もし,ここまでで何のことを云っているか見当がつかないようであれば,
まづは自分のプラットフォーム用のバイナリを入手することを試みるのがよい.
下記URLの日本のサイト(上段)は日本語対応のPythonで,WindowsとMacintoshの
バイナリ,およびソースファイルが置いてある.下段は公式サイトで,各種プラッ
トフォームのバイナリがある.ここや自分のOSのサイトでバイナリーを探してそ
れでも見付からない時にソースから構築することを検討するべきである.その際
はC言語が話せるか,この種のフリーソフトのインストール経験のある者の助け
が必要になるかもしれない.
日本のサイト http://www.python.jp/Zope/download
公式サイト http://www.python.org/download/
3つの環境変数 PATH, PYTHONPATH, PYTHONSTARTUP を正しく
セットする必要がある.
- PATH
- はOSのShellのパスである.簡単に説明すると実行ファイルを
置いてある場所である.Pythonを使用するにはpythonが置かれた場所が,
PATHに含まれている必要がある.PATHに関する,これ以上の説明は
Arthur and Burns (1997); Kernighan and Pike (1984); 砂原他 (1996)を参照されたい.
- PYTHONPATH
- はPythonのモジュールのパスである.Pythonのスクリ
プトでモジュールが呼び出された時に,この変数のリストから,そのモジュール
の位置を特定する.
- PYTHONSTARTUP
- は対話的コマンドライン(後述)を起動した時に必
ずこの変数に記述されたファイルを実行する.たとえば,歓迎のメッセージを表
示するスクリプトを含めておけば,Pythonを起動する時にその歓迎のメッセージ
が表示される.また,毎回インポートするモジュールをスクリプトに記述してお
くことにより,毎回手入力でモジュールをインポートする手間を省略できる.
C shell系(csh, tcsh)では環境変数は次のように設定する.
set path = ($path /usr/pkg/bin)
あるいは,次のようにする.
setenv PATH "${PATH}:/usr/pkg/bin"
B shell系(sh, bash, ksh)では,
PATH=$PATH:/usr/pkg/bin ; export PATH
のようにする.
なお,C/B shell共に,普通に使用しているのなら,PATHの設定はちゃん
となされている筈である.PYTHONPATHもたいていのインストールで適切に
設定される.あとから自分でモジュールを追加した時には,その場所を
PYTHONPATHに追加しなければならない.
Pythonは対話的コマンドラインを実装している.
Unixでいればshell,WindowsでいえばDOS窓のようなものを想像すればよい.
端末で,次のように起動する.
% python
Python 2.4.1 (#1, Dec 16 2005, 22:46:02)
[GCC 3.3.3 [NetBSD nb3 20040520]] on netbsd2
Type "help", "copyright", "credits" or "license" for more information.
>>>
最後の>>>がプロンプト(促進forユーザーからの入力)である.これに下
記上段print文を与えると下段の結果を得る.
>>> print 'There is a gap between stimulus and response.'
There is a gap between stimulus and response.
対話型コマンドラインから抜けるにはEOT文字(符号) 1.2を与えればよい.
Unix系の端末ではEOT符号はControl+D(しばしばC-D/Ctrl-Dと表記される)
である.WindowsではC-Zの場合もある.
対話型の使いかたは,簡単にテストでき結果を見ることができるのが取り柄であ
るが,毎回同じことを入力していては埒があかない.それで,プログラムをファ
イルに記述し,それを実行することで楽ができる.これを再利用という.
計算機の利用・プログラムは再利用性を高める方向に進化してきた.
Pythonのプログラムはコンパイル(計算機が直接理解できる0/1の言語[Binary]に
直す作業)をプログラムが呼び出される度に行うスクリプト型の言語である.あ
らかじめコンパイルしておかなければいけない言語をコンパイル型の言語という
(たとえばC言語).その都度コンパイルするのは不便に思えるかもしれないが,
小規模のプログラムを少し手直しして実行させる,という作業はスクリプト型の
ほうがやりやすい.
スクリプトは,
% python script.py
とすれば,スクルプトファイルscript.pyがPythonに渡され実行される.
Unix系では更に簡単な方法が用意されていて,
% ./script.py
とすれば,そのまま実行される.ただし,ファイルが実行可能属性をもっていな
ればいけない.
ファイルに実行可能属性を与へるには,
% chmod +x script.py
とすればよい.
普通はPATHにカレントディレクトリ[今いるところ]は含まれていない(理
由は砂原他 (1996) p.30参照)ので,カレントディレクトリを指す``
./''が必要である.また,スクリプトをどの処理系1.3に渡すかをスクリプトの先頭に書いておく必要がある.pythonの場合,下
記のやうになる.
#! /usr/pkg/bin/python
書式を説明する.普通,行頭の#はコメントとして解釈されるが,ファイ
ルの先頭でしかも!がつくと特別で,このspellが記述された場合,ファ
イルの内容がその次に書いてあるファイル(この場合は
/usr/pkg/bin/python)に渡される.この場合は,NetBSDを想定している.
NetBSDではpythonは/usr/pkg/binにインストールされる(pkgシステムを
用いた場合).FreeBSDでは/usr/local/binにインストールされる(portシ
ステムを用いた場合).Linuxでは/usr/binか/usr/local/bin で
あるが,場所も最初からインストールされているかも,ディストリビューション
によって異なる.MacOS X(10.2-10.4 )の場合は./usr/binに最初から
インストールされている.野良ビルドといって既存のインストールシステムを用
いず自分でインストールする場合は特別に設定しなければ
/usr/local/binとなる.スクリプトはPythonがインストールされている
全ての計算機で動く(もちろんそのスクリプトが正しいものなら)が,別のOSの計
算機にスクリプトを移して使用する場合に,いちいち先頭をそのOSのPythonにあ
うように書きなおさなければいけない.これは面倒である.このようなUnixでは
環境の違いによる差異を埋める方法も用意されていて,
#! /usr/bin/env python
と記述すると,自動的にPATH'の中から最初に見付かったPythonにスクリ
プトを渡してくれる.複数のpythonを入れている時には,思ったpythonに行くと
は限らないので注意が必要である.その場合は渡したいpythonを記述してあげる
必要がある.例:
#! /optional/bin/python21
手続き型プログラミングというのは,計算機が行うべき演算の手続きを記述した
プログラムで,自然言語で云えば,料理のつくり方を述べた文章が近いだろう.
手続き型プログラミングはオブジェクト指向プログラミングの前の世代のプログ
ラミグの流儀であって,当然,オブジェクト指向プログラミングではないが,そ
れは流行遅れとか,時代錯誤ということではない.現在でも立派に通用するやり
方である(ただ,手続き型では越えがたい壁を越えるためにオブジェクトは導入
されたのである).Pythonそのものはオブジェクト指向で設計されているが,手
続き型でもプログラミングできるようになっている.プログラムの基礎を修得す
るために,最初に手続き型プログラミングから述べる.
Pythonのオブジェクト指向性は随所に発揮されるため手続き型でプログラミング
しても,自然にオブジェクトを使うようになっている.これはオブジェクト指向
とは何かを実感するにはよい方法に思える.Pythonを手続き型的に使うことによ
り,『オブジェクト指向は手続き型プログラムが目指したもの--見通しをよさ
と再利用性--を追求した結果,論理的帰結の一つとして導出された』ことが理
解できるだろう.
プログラムとは何か. 計算機がしているのは, 画面でたとえ, どんなにハデなこ
とが起きていようとも整数(正確には0を含めた自然数)の足し算と引き算であ
る. プログラムを用いて整数の足し算と引き算しかできないものを人が理解でき
使える形に変え, 人間の用となる知的な道具に変身させる.
the_most_famous_nd_shortest.py
#! /usr/bin/env python
print "Hello, World!"
これを実行すると, ``Hello, World!''というメッセージが端末に出る. これは
最も有名で短かいプログラムで, CでもPerlでもどの教科書でも最初のほうに例
として出てくるサンプルプログラムである. ここで, printの引数を``Hello,
World''から ``Goodbye Daring''に変えるとどうなるだろうか? メッセージが
``Goodbye Daring''に変わるのである. 実際にやってみよ. また, メッセージを
変更するのではなくて, また,メッセージを``Goodbye Daring''にしたプログラ
ムを一から打ち込んでみよ. そして, 手間やタイプミスを比較せよ. さらに,次
のプログラムを導入してみよ.
three_times.py
#! /usr/bin/env python
print "Hello, World!"
print "Hello, World!"
print "Hello, World!"
これは要するに``Hello, World!''を三回出力するプログラムであるが,これを
``Hello, World''から ``Goodbye Daring''に変えよ.ウンザリしないだろうか?
また一から書きなおすなんて,なにか無駄なことをしている気がしないだろうか.
ここで,定数という概念を導入する.数というが,これは,この概念が数学に由
来しているので数を称しているが数でなくてもよい(この場合は文字列を示す).
しかし計算機上では全てのものは数字の羅列に他ならないため,数という表現は
いみじくも正しい.
three_times2.py
#! /usr/bin/env python
message = "Hello, World!"
print message
print message
print message
この例文ではmessage定数を``Goodbye Daring''に変更するだけで足る.
これをテキストエディターで検索置換で処理する場合と比較せよ.定数を設定す
る方が,より問題の本質に近付いた気がしないだろうか? この命題に賛
成できなくても,上述の動作を相互に比較したらば 次のような命題が導かれる
であろう.
前に書いたプログラムの機能を書きかえて別の機能に変えたほうが,
一から書くより楽.
Unixでは, 次のような格言がある.
しかし, このプログラム, 私には面白くない. なぜか, それはフィルターになっ
ていないからである. つまり, このプログラム(ここではHellow, World型と称す)
は入力を必要としない. 入力を必要としないプログラムは, 時限爆弾のように
決めたことを実行するだけの用途には足るかもしれないが, 時限爆弾とて設定が
複数あるとHellow, World型のプログラムでは対応しきれないところがある. 設
定ごとに, コードのパラメータを修正するよりは, 引数に設定を入れる(入力!)
ようにした方が楽であろう.
それに, データ処理は入力としてデータを入力しそれを処理して出力することで
ある. そこで入力を必要としないプログラムの解説はここで中止し, 入力を必要
とするプログラムを先に紹介する.
考えてみると, 人間も外界から自分の感覚器を通じて情報を得(つまり入力であ
る), その人なりに分析(つまり,データ処理)し自分の行動に反映させる(出力).
人間もデータ処理をしている.
最も簡単なフィルタは
入力をそのまま出力にコピーするフィルターである.
filter.py
#! /usr/bin/env python
import sys
for line in sys.stdin.readlines():
print line,
filter_while.py
#! /usr/bin/env python
import sys
while 1:
line = sys.stdin.readline()
if line=='' : break
print line,
使い方
filter_while.py < spam.data
filter_for.py
#! /usr/bin/env python
import fileinput
for line in fileinput.readlines():
print line,
使い方
% filter_for.py spam.data
Pythonのprintは書式を指定した表示ができる.これはC言語の
printf函数と同じ実装である.Pythonに限らずC言語で記述されている言
語はprint(あるいはそれに類する機能)をC言語のprintfを借用し
ているので,同じ書式で同じ機能が実装されている.
printfと同じであるから,完全な仕様は
% man printf
% man 3 printf
% man 9 printf
で得られる.ここではよく使用する使い方のみ説明する.
書式付printの構文は
%[flag][min_width][.precision]conversion
で与へられる.[ ]はoptionalであるが,%
とconversion変換文字は必須である.変換文字として下記のうちどれかを指定する必要がある.
| d |
integer |
| i |
integer |
| o |
octal |
| x |
hexadecimal(lower case) |
| X |
hexadecimal(upper case) |
| c |
first character |
| s |
string |
| f |
floating point (123.456) |
| e |
floating point (1.234e-7 for
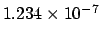 ) ) |
| E |
E is used for `e' |
| u |
unsigned integer |
| g |
f or e in minimum space |
| G |
F or E in minimum space |
使用例を示す.
>>> spam=2951
>>> print "Decimal: %d, Octal: %o, Hexadeci %x" %(spam,spam,spam)
Decimal: 2951, Octal: 5607, Hexadeci b87
>>> geologist="hammer"
>>> print "Geologist is an earth scientist with %s." %(geologist)
Geologist is an earth scientist with hammer.
%d, %o, %xにより整数の基数を十進数,8進数,16進数で表示できる.
xを大文字にすると,abcdefが大文字になる.
文字列は%sで表示する.次は浮動小数点の例である.
>>> avogad_f=602000000000000000000000
>>> avogad_e=6.02e+23
>>> print "Avogadro Number is \n %f\n or\n %e" %(avogad_e,avogad_f)
Avogadro Number is
601999999999999995805696.000000
or
6.020000e+23
>>> print "or\n %E" %(avogad_f)
or
6.020000E+23
アボガドロ数として与へた値と返ってくる値が微妙に異なることに注意されたい.
これは2進数で十進数の浮動小数点を書き示す際の誤差である(詳しくは型の項目
で説明する).
また,複数の引数を与へる場合には(var1 ,var2)で括らなけ
ればいけない.これはタプルにすることを示す.また,文中に\nとある
のは改行記号である.このような記号には下記のようなものがある.
\e |
escape |
0x1b |
\a |
bell |
0x07 |
\b |
back-space |
0x08 |
\f |
form-feed (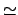 new page) new page) |
0x0c |
\n |
new line (改行) |
0x0a |
\r |
carriage return (復帰) |
0x0d |
\t |
tab (horizontal) |
0x09 |
\v |
vertial tab |
0x0b |
ちなみに,%と表示するには%%とする.
>>> print "%%" % (4)
%
ところで,最初のprint文で整数のspamを様々なフォーマットで整
形している.ところが,計算機の習慣として8進数は0をつけて04の
ように表示する.同じく,16進数は0xまたは0Xとつけて0x4
のように表示するのが習慣である.これをサポートするのはflagである.
flagはそれ以外にも左揃えや符合つけ,スペースで桁揃えや0で開き桁を
埋めるなど様々な機能がある.一覧は下記のとおり.
| - |
left adjustment |
| + |
always be signed |
| _ |
spaced for blank |
| 0 |
fill 0 character padding |
# |
print in an alternative form |
| |
o(octal): string 0 prepended |
| |
x(hexadecimal): string 0x prepended |
| |
X(Hexadecimal): string 0X prepended |
| |
e E f g G: always contain a decimal point |
_はスペースを意味する(_と入
力するのでない).それでは,使ってみやう.
>>> print "Decimal: %#d, Octal: %#o, Hexadeci %#x" %(spam,spam,spam)
Decimal: 2951, Octal: 05607, Hexadeci 0xb87
>>> # 8進数,16進数に0,0xを付ける
>>> print "%+d" %(spam) # 常に符合をつける.
+2951
>>> print "%#f" %(spam) # 常に小数点をつける.
2951.000000
他のパラメータは幅が設定されないと意味がないので.あとで説明する.
min_width(minium width)で表示する幅を明示する.幅を越える場合は,
幅を広げて表示する.幅より狭いところは_で埋める.
*を指定した時は,幅は引数(int)の値を使用する.
>>> print "%08d % 8d %-8d" % (spam,spam,spam)
00002951 2951 2951
0は桁数の残りを0て埋める._はスペースで埋
める.-は幅を左詰めで表示する.
precision(精度)はconversionの種類によって挙動が異なる.
| d i o x X |
表示桁数(余りスペースは0で埋める) |
| e E f g G |
小数点以下の表示桁数 |
使ってみやう.
>>> print "%8.3f" % 1234.5678
1234.568
>>> print "%8.3e" % 1234.5678
1.235e+03
コメントとは何か.コメントはコードの中に含まれる人間が読むための文章のこ
とである.プログラムが複雑になるにつれ,コードの役割や機能的位置づけが人
間には難解になる.プログラムの文脈的明瞭さを補うためにコメントは記述され
る.
コメントは何で示されるか.Pythonのコメントは,行頭の#で示される.
#以降,その行の改行まではコメントと見倣される.
よいコメントとは何か? よい見本がダイレクトに「よさ」を伝えるように,
悪い見本も逆説的に「よさ」とは何か語る.次のようなコメントは悪いコメント
である.
dmin = min / 60 # minを 60 で割る
なぜこのコメントが悪いコメントか? それは,そんなことは読まなくてもわか
るからである.
見てわかることを書いてはいけない.
更に次のコメントは最悪である.
dmin = min / 60 # minを 20 で割る
なぜか.コードでは60で割っているのに,コメントでは20で割るとなっている.
これではどちらが正しいのかわからない(たいていはコードが正しいのだが).コー
ドを見ればわかることをわざわざ書いた場合,往々にしてこういう事態になりや
すい.最初にコメントした時と状況が変って,それを反映するためにコードを訂
正したのだが,コメントの訂正は忘れがちである.次のようなコメントがよいコ
メントである.
dmin = min / 60 # 分(min)を時(dmin)に変換.
この例では,なぜ 60で割らなければいけないのか,よくわからない.それをコ
メントで補うのである.
モジュールは,函数(群)を再利用可能にするために,命令群をまとめて外部函数
化したものである.モジュールはブラックボックスとなるので,中でどうなって
いるか気にせず,インプットとアウトプットにだけ注意を払えばよいので,注意
力の節約になる.
import sys
これによりsysモジュールが組み込まれる.
利用するには
sys.exit()
のようにする.
exitには()がついていることに注目.この()は函数であることを示す.たとえ函
数に引数がなくても()は必要である.
函数ではなくて定数である例を示す.
import math
mathモジュールは数学でよく使う函数やら定数をモジュール化したものである.
この中には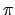 の値も含まれている.
の値も含まれている.
print math.pi
とすると,の値が得られる.
print math.sin(math.pi/2)
math.sinは函数なので括弧「()」が必要で,かつ括弧の中はradianで表記
しなければいけない(各モジュールの詳細についてはPythonのLibrary Reference
を参照されたい).
モジュールによって配列が得られることもある.次に重要な例を示す
print_argv.py
#! /usr/pkg/bin/python
import sys
print sys.argv
これに適当な引数を与へて実行してみる.
% ./print_argv.py a b c d e f # 実行形式としてスクリプトを実行
['./print_argv.py', 'a', 'b', 'c', 'd', 'e', 'f']
% python print_argv.py a b c d e f # Pythonの引数としてスクリプトを実行
['print_argv.py', 'a', 'b', 'c', 'd', 'e', 'f']
このモジュールのインスタンスは引数を配列をして格納する.配列の最初には,
スクリプトのファイル名が格納されていることに注意されたい.なお,配列の番
号は最初が0から始まる(後述)ので,sys.argv[0]がスクリプト名になる.
最初に引数(この場合ではa)はsys.argv[1]となる.このモジュール
によりスクリプトの引数をスクリプトに伝えることができる.
モジュールはオブジェクトの一つである.
インスタンス(instance)とは事例やある命題の論拠となる事実のことを一般には
意味する.計算機内では,メモリ内の空間を占有(occupy)するデータの実体のこ
とである.通常は変数により参照される.クラスとオブジェクトの関連で使われ
る場合はオブジェクトと同義語である.
クラスとはオブジェクトの種類で,属性とメソッドが定義される.
互いに関連のあるデータ要素とそれらに実行できる操作を集めて1つの単位とし
て扱えれるようにしたもの.
実世界のなにかを抽出してあり,計算機上で操作できるようにしたもの.
私の理解では,データ(data)とは, そこから推論(inference)を得ることができ
る証拠(evidence)である.
データの型を決定する方法には動的型付け(dynamic)と静的型付け(static)があ
る.Pythonは動的な型付けをする.静的型付けでは最初に型を定義する.定義と
異なる型に対して演算がなされるとTypeErrorでプログラムは停止する.中には
実行前に,プログラムを検査して定義と異なる型が代入される可能性がある場合,
検査段階で停止する言語もある2.2.動的な型付けでは代入したときに型が決定される.
異なる型のものを代入しても,その時点で型が変更される.但し,異なる型のも
のを演算(足し算や結合)することはできない.どちらの型に合せるべきか非明示
であるからである(perlのようにどちらに合せるか決めている言語もある).たと
えば,
q = 7
としてから
q = 'seven'
とするのはvalidである.前者では型が整数として定義されるが,後者になると
整数という型は破棄され,文字列という型に変更される.しかし,
q1 = 7
q2 = 'seven'
としてから
q3 = q1 + q2
ということはできない.整数と文字列の足し算(あるいは結合?)は定義されてい
ないためである.
文字列は文字(文字の型については後述する)の羅列(シーケンス)である.別に言
語の体裁をしている必要はない.文字列はシングルクウォート
'something'で括られるかダブルクウォート "something"で括ら
れるものがある.また複数行にわたる(つまり改行を含む)文字列はトリプルのダ
ブルクウォートで括ることができる.
o = 'L"oben Brau, magischen Kr"afte'
# 「'」でクウォートしている中には「"」が使える.
q = "Never attempt to write something you don't care about"
# 「"」でクウォートしている中には「'」が使える.
r = 'Never attempt to write something you don\'t care about'
# バックスラッシュ「\」で 「'」をエスケープする.
quote = """Sloppy authors rarely get published, ---
but perfect authors never,
all you have to do is produce a manuscript
which says something worthwhile,
says it well and is not sloppy
`my best work at this time' """
この方法では改行の他,タブ(インデント)などの制御文字も含むことができる.
たとえば文字列中で改行がはいっているところはprint文で改行として表
示される.文字列中に別の場所に改行コードを入れるには,
quote = """Sloppy authors rarely get \
published,\n but perfect authors never."""
のように改行を\nとして入力すればよい.と同時にgetの行の終
わりの改行は\を用いて無効にしてあげる必要がある(これをエスケープ
と呼ぶ).そうしないと,getと publishedの間に改行が入り,
published,とbutの間にも改行がはいってしまう.
では,改行を示すシンボルとしての\nを\nとして表示したい時は
どうすればよいのだろうか.
quote = r"""Sloppy authors rarely get \
published,\n but perfect authors never."""
とすると,
>>> print quote
Sloppy authors rarely get \
published,\n but perfect authors never.
のように\や\nはそのまま表示される.
これをraw文字列と云ふ.
文字列演算子には連結(結合)の+と反復の*がある.
>>> s = "abra"
>>> t = "karabra"
>>> print s+t
abrakarabra
>>> print s*2
abraabara
>>> print 2*s
abraabara
文字列の定義により文字列は文字のシーケンスであるから,シーケンスとして処
理できる.シーケンスとしての処理は,配列(後述)の操作と同じである.
sq = "abcdefg"
という文字列が与えられたとする.qに添字[n]を付けること
によって,シーケンス上での位置を特定することができる.これによりシーケン
スから部分的に要素(つまり文字または部分文字列)を取り出すことができる.
シーケンスから部分シーケンスを抽出することをスライスと呼ぶ.
>>> print sq[1]
b
この場合,添字はオフセットを示す.sq[1]は一番目の要素だからa
だと思ってはいけない.一番目の要素は計算機では0番目である.[1]は二
番目である.[-1]は後から一番目を示す.こういう表記をオフセット表記
とふ.:を用いて,ある位置からある位置までを指定することもできる.
>>> print sq[-1]
g
>>> print sq[0:3]
abc
後者の0は最初を意味し,3は三つめのオフセットを指定している.
:で区切られているので,三番目の文字の手前までを指す.オフセットに
ついては,下記を参照されたい.
|
オフセット |
0 |
|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
|
|
|
|
|
シーケンス |
| |
a |
| |
b |
| |
c |
| |
d |
| |
e |
| |
f |
| |
g |
| |
|
|
|
|
|
|
逆オフセット |
-7 |
|
-6 |
|
-5 |
|
-4 |
|
-3 |
|
-2 |
|
-1 |
|
|
|
|
|
|
|
ちなみに
>>> sq[:0]
'abcdefg'
>>> print sq[:0]
abcdefg
>>> print sq[1:]
bcdefg # 最初の一文字だけ除いた部分文字列
>>> print sq[:-1]
abcdef # 末尾の一文字だけ除いた部分文字列
である.
自然言語(つまり人間の通常用いる言語)では数字の最初(数学で言う自然数)は1
からはじまるが,計算機上では数字の最初は0からはじまる.これは奇異に見え
るかもしれないが,人間が1から数えるのは,「ない」という状態が存在するこ
とを発見するより先に数字を発明したから(詳しくは吉田 (1955))で,人間
の歴史に制約されたモノの考え方である.また,自然言語でもBritish English
では,日本語の1階をgrand floorと言い,2階をfirst floor, 3階をsecond
floorのように計算機と同じ数え方をするものがある.単純に始めだけの違いで
しかないが,一から始めるか,零から始めるか,大いなる問題だ(足し算系では1
ずれるだけで大した違いにはならないが,掛け算系ではシリアスが違いがある.
1はN倍すればNになるが0はN倍しても0である).
最後に注意すべきことは,スライスで文字列の一部を切り取れるが,それに代入
することはできないことである.たとえば
>>> sq[2]
'c'
>>> sq[2]="g" # Greekの第三文字はΓであってローマ字でいうgだから(冗談).
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: object does not support item assignment
>>> sq[2]
'c'
のように,Pythonの文字列は部分文字列の変更を受けつけない.
文字と文字列は異なる.文字列は文字のシーケンスである.C言語では文字とい
う型があって,それは0-255までの整数という意味であるが,Pythonには文字と
いう型はない.Pythonでは1文字は1文字からなる文字列である.Pythonで文字列
といっているものはC言語では文字配列である.
計算機上の整数は数学の整数と異なって上限がある.上限は普通,MAXINT
という定数名をもち,32bit計算機では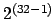 の数(約20億)が識別できる
から,上限は20億である.上限を把握しておくことは重要である.上限を越える
値が入力(overflow)された時に,そのプログラムがどのような挙動をするか,こ
れが問題なのである.Pythonではoverflow flagが設けてあり,overflowが生じ
たら直ちにエラーで停止するが,そうではないプログラムではoverflowした後も,
そのままプログラムが続行することもある.これはセキュリティホールになる以
外にも,エラーがでないので,おかしいことに気がつかないまま計算結果を信用
してしまう危険がある.
の数(約20億)が識別できる
から,上限は20億である.上限を把握しておくことは重要である.上限を越える
値が入力(overflow)された時に,そのプログラムがどのような挙動をするか,こ
れが問題なのである.Pythonではoverflow flagが設けてあり,overflowが生じ
たら直ちにエラーで停止するが,そうではないプログラムではoverflowした後も,
そのままプログラムが続行することもある.これはセキュリティホールになる以
外にも,エラーがでないので,おかしいことに気がつかないまま計算結果を信用
してしまう危険がある.
Pythonで定義される整数には MAXINTの上限がある整数(C言語のLongに相
当)と,上限のない整数がある.前者は56789,後者は99999999999999999Lのよう
に記す.普通に算用数字で記述すれば10進法と解釈される.8進数で示すために
は, 015, 0132のように先頭に0をつければよい.ちなみに,015, 0132はそれぞ
れ10進数の13, 90である,ASCIIではそれぞれ改行(CR)と大文字のZである.16進
数で表記するためには先頭に0xをつければよい.改行の015は0xd,Zは0x5aとな
る.
0-127までのASCIIの範囲内(7bit)ではord()とchr()という函数が
用意されている.chr()は,引数の数字(10進数であれ,8進数であれ,16
進数であれ)をASCIIのコード番号を解釈してそれに対応する文字を返す.ord()は引数の文字(一文字に限る)に対応するASCIIのコード番号を返す.基数
を変換する函数も用意されていて,16進数に変換する函数がhex(),8進数
がoct()である.Pythonでは数は10進数で表記されるので,たとえ16進数
で入力しても,表示される時は10進数である.hex()を用いて明示的に16
進数に変換した数を10進数に戻すには,int()(整数にする函数)を用いる.
int()は二番目の引数に基数を指定できるので,int('0x5a',16)の
ように基数を与えて変換する.
>>> ord('Z')
90
>>> chr(90)
'Z'
>>> chr(13)
'\r'
>>> chr(015)
'\r'
>>> chr(0xd)
'\r'
>>> x = 0xd
>>> print x
13 # 10進数で表記される.
>>> x
13 # 中身も10進数に変っている.
>>> x = hex(x) # 16進数に変換
>>> print x
0xd
>>> x
'0xd' # stringの型で入っていることがわかる.
>>> x[1:2] # だから,このように
'x' # スライスできる.
>>> int(x,16) # 10進数に再変換
13
>>> int(0xd,16) # 値を直接入力すると...型が違うのでエラーになる.
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: int() can't convert non-string with explicit base
>>> int('0xd',16) # だから,stringとしてquoteしてあげる必要がある.
13
算術演算子として「 + - * / % **」が用いられる.それぞれの使い方は,
中学校の数学で習ったとおりである.ただし,「*」は掛け算である.
ASCIIに「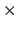 」という記表はないためである.「
」という記表はないためである.「/」は割り算,
ASCIIでは「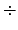 」という記号はないし,「
」という記号はないし,「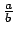 」という表記は困難
であるため.「
」という表記は困難
であるため.「%」は剰余といって,整数の割り算において割った余りを
指す.たとえば 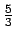 は1あまり2である.これを商を1,剰余を2と云ふ.
「
は1あまり2である.これを商を1,剰余を2と云ふ.
「5%3」の戻り値は2である.「**」は累乗である.x**2
はxの2乗を意味する.これらは,他のプログラム言語でも用いられている表記法
である.Pythonの方針として演算子にしても函数にしても,わかりにくい記表を
避けている.
Pythonではビット演算子も使える.
>>> x = 1 # 1 = (0001)
>>> x << 2 # 2 bit 左にシフトする.
4 # 4 = (0100)
>>> x | 2 # (0001)と(0010)の論理和
3 # (0011) = 3
>>> x & 1 # (0001)と(0001)の論理積
1
>>> x & 3 # (0001)と(0011)の論理積
1
ビット演算の詳細についてはWarren (2006); 高林他 (2006)を参照された
い.
浮動小数点は数学でいう実数に相当するが,計算機上の浮動小数点数は実数とは
大きく様相が異なる.数学では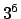 のように仮数と指数に分解して数
を表現する.浮動小数点では底は常に10である.内部ではもちろん底は2である.
ここから来る齟齬は数学的(あるいは計算機科学的)にはなかなか面白いが,特に
注意が必要になることだけ述べる.同じ値となる数を比較しても等しくならない
事態である.たとえば,4.0000...になるべき数が計算方法,あるいは計算の順
番によって,4.00000...0001とか,3.99999999....となることがある.この二つ
を比較しても等しくないという結果になる.浮動小数点を比較する時は,ある許
容範囲の閾値を設けて,「まる」めてから比較するか,あるいは両者の差をとっ
て,その差が許容範囲以下であれば等しいと見倣す,のように判別すべきであ
る.
のように仮数と指数に分解して数
を表現する.浮動小数点では底は常に10である.内部ではもちろん底は2である.
ここから来る齟齬は数学的(あるいは計算機科学的)にはなかなか面白いが,特に
注意が必要になることだけ述べる.同じ値となる数を比較しても等しくならない
事態である.たとえば,4.0000...になるべき数が計算方法,あるいは計算の順
番によって,4.00000...0001とか,3.99999999....となることがある.この二つ
を比較しても等しくないという結果になる.浮動小数点を比較する時は,ある許
容範囲の閾値を設けて,「まる」めてから比較するか,あるいは両者の差をとっ
て,その差が許容範囲以下であれば等しいと見倣す,のように判別すべきであ
る.
物理を取り扱う向きにはうれしい複素数が定義されている.複素数は
(2+4j)のように実数部と虚数部にわけてガウス表記をする.ただ数学と
異なるのは,虚数単位をiではなくjで示すことである.ラジカルな
数学者のように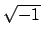 のようには示さない(示せない).物理では虚数単位
をjで表記することは稀ではない.たとえば,電磁気学ではiに電流
の意味を与えることが通用していたため,虚数単位にiを避けてjと
していた.計算機では
のようには示さない(示せない).物理では虚数単位
をjで表記することは稀ではない.たとえば,電磁気学ではiに電流
の意味を与えることが通用していたため,虚数単位にiを避けてjと
していた.計算機では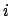 は整数の一時変数にしていることが多いので避けたの
もかもしれない(数学でもそれは同じだが数学でを使いづつけ,プログラム言
語でそうではない理由は未解決).
は整数の一時変数にしていることが多いので避けたの
もかもしれない(数学でもそれは同じだが数学でを使いづつけ,プログラム言
語でそうではない理由は未解決).
真偽値は論理学でいう真理値である.真理値というのは,ある命題が正しい時は
1であり,正しくない時は0になる値のことである.命題とはたとえば下記のよう
な文のことで,
命題:アリストテレスはアレキサンダー大王の家庭教師であった.
真が偽かを可能性として決定しうる文のことである.上記の命題は歴史を紐解け
ば真偽を決定できる.この時の真偽を値にしたものが真理値である.真理値は命
題の正しらしさの比率(割合)と思えばよい.ただし,普通,命題は正しいか正し
くないか1か0の二通りの離散値しかない(もし,0.3とか0.5とか0から1の間の複
数の値をとることができるのであれば,それは真理値というよりも確率である.
真理値も確率も定義の根本は同じである.「それが真実である割合」である).
真理値は,真理値を論理学と数学に導入したBoolの功績を賛えて,Booleanとも
呼ばれる.
Booleanの演算子は全てspell-outする.
(x=1) and (y=0)
(x=1) or (y=0)
x==1
x!=1 # これは x<>1とも表記できる.
not x
2+3*5+1のような式は,先に掛け算の3*5が実行されてから残りの
足し算が実行される.中学校で習ったことと思うが,プログラム言語でも同じで,
演算子には,それぞれ強さが定義されていて強い順に演算される.乗法
({*, /})のほうが加法({+, -})より強い.累乗(**)は乗
法よりも強い.演算の順番を変えたいときは(...)を用いればよい.
2+3*(5+1)とすれば5+1が先に演算される.(...)を用いる
時の注意は2つある.一つは(...)が対応していない(閉じていない括弧や
閉じ括弧だけある場合)とエラーになるということ.もう一つは,括弧が多すぎ
る文章はそれがたとえ正しく対応していても人間には読みにくい.プログラムは
コンパイラーだけが読むものではない.人間が書き,人間が読み,人間が訂正す
るものである.
コレクションは基本的な型からなる変数の集合(コレクション)である.
リストも配列も,項目が一続きになったものである.リストと配列の違いは,リ
ストはサイズを後から変更できるが,配列はできないこと, 逆に,配列はイン
デックスがついているが,リストはインデックスがついていない.配列なら,A
配列の3番という風に,配列の中の項目を数字で呼び出せるが,リストはそうは
いかない.ところが,Pythonのリストはインデックス化されていて,配列とリス
トの長所が統合された恰好になっている.そこで,リストと配列を区別せず,配
列と呼ぶ.Pythonでは配列を作成したり,配列の項目を参照するには,
[ ]を使用する.
文字列の項目で少し説明したが,文字列は配列の一種なので,
配列のインデックスのつきかたは文字列と同じく,先頭が0のオフセット表記で
ある(ただし,配列はあとから要素の一部を変更できるが,文字列は一部だけの
変更はできない).
>>> DNA = [] # 空配列を生成
>>> DNA=["a","b","c"] # 値を代入.
>>> print DNA
['a', 'b', 'c']
>>> print DNA[0]
a
>>> DNA[-1] # print文でない時,クオートされて出力される.
't' # つまり,データの入力された時の恰好になる.
配列の内容(値)を変更するには新しく代入すればよい.また,配列に新しく要素
を付加にするには,append()演算子(正確にはメソッド)を用いる.
>>> DNA[1]="g"
>>> DNA
['a', 'g', 'c']
>>> DNA.append("t")
>>> DNA
['a', 'g', 'c', 't']
配列は入れ子にすることもできる.
>>> Science =["math","phys","chim","biol","geol"]
>>> print Science
['math', 'phys', 'chim', 'biol', 'geol']
>>> Geology = ["petro","strati","volcan","geogra"]
>>> Science[4] = Geology
>>> print Science
['math', 'phys', 'chim', 'biol', ['petro', 'strati', 'volcan', 'geogra']]
配列の中に配列が格納されているのが[ ]の位置からわかる.入れ子になっ
た配列の項目を参照するには[ ]を二回(あるいは必要なだけ)並べる.こ
の方法をもちいて,行列(や,もっと複雑な集合)を表すことができる.
>>> print Science[4][1]
Stratigra
>>> Eigen = [[1,0],[0,1]] # 二元の正方行列の単位行列
配列の削除はdelを用いる.結合は文字列と同じで+である.
*を用いて同じ値をもつ項目が複数回繰り返す配列を作成できる.
最後に,len()函数により配列の長さを調べることができる.
配列を読み込み逐次処理するまえに,配列の長さが知りたい時に重宝する.
>>> del Science[1]
>>> print Science
['math', 'chim', 'biol', ['Petrol', 'Stratigra', 'Volcanol', 'Geogra']]
>>> eigenvector = [1]*3
>>> print eigenvector
[1, 1, 1]
>>> len(eigenvector)
3
>>> len(Science)
4
>> len(Science[3])
4
タプルは変更のできないリストである.タプルに対して変更しようとすると,エ
ラー(TypeError)によりプログラムが終了することで,タプルが破壊されること
を防ぎ,プログラムに誤りがあることを,ユーザーに伝える.表記は,( )
で定義し, [ ]で参照する.
>>> Colour = ("Red","Grn","Blu")
>>> Colour[2]
'Blu'
他の言語ではハッシュということが多い. ディクショナリという名前からわかる
ように参照表のことである.たとえば,
netbsd.org 204.152.190.12
freebsd.org 69.147.83.40
openbsd.org 199.185.137.3
gnu.org 199.232.41.10
これは,DNA(Domein Name Server)のIPアドレスとドメインネームの対照表の見
本であり,ディクショナリとしての機能を果す.ハッシュの作成(初期化)と,代入,追加
代入は下記のとおりである.
>>> DNS ={} # 初期化
>>> print DNS
{}
>>> DNS ={"netbsd.org":"204.152.190.12",\
... "freebsd.org":"69.147.83.40",\
... "openbsd.org":"199.185.137.3"} # 一括代入
>>> print DNS
{'openbsd.org':'199.185.137.3','freebsd.org':'69.147.83.40',\#継続行
'netbsd.org':'204.152.190.12'}
>>> DNS["gnu.org"]="199.232.41.10" # 追加代入
>>> print DNS
{'openbsd.org':'199.185.137.3','freebsd.org':'69.147.83.40',\#継続行
'gnu.org':'199.232.41.10','netbsd.org':'204.152.190.12'}
肝心の,ハッシュを参照するには[ ]の中に自分の探したいものを入れるだけである.
>>> print DNS["netbsd.org"]
204.152.190.12
クラスはPythonで唯一定義できる型である.いいかえるとPythonにおけるユーザー
定義型は全てクラスである.たとえば,書誌データ型というのをここで定義する.
書誌データというのは,下記のようなものである.
@book{kandr98,
author="Brian Kernighan and Dennis Ritchie",
title="The {C} programming langrage",
edition=2,
year=1988,
publisher="Prentice Hall",
address="New Jersey",
pages=274,
}
これはBIBTEXというアプリケーションのフォーマットで記述した
ある本(K&Rと称されるC言語の著名な本(Kernighan and Ritchie, 1988))の書誌データである.
これをPythonでのクラスとして再定義する.
class Book:
def __init__(self,author,title,edition,year,publisher,pages)
self.author = author
self.title = title
self.edition = edition
self.year = year
self.publisher = publisher
self.address = address
self.pages = pages
}
まづ,インデントで系統的に字下げされていることに注意されたい.インデント
は伊達ではなく,Pythonは段落の区切りをインデントで理解する.そのため,イ
ンデントが揃っていないと文法的に間違った文とされる.さて,ここで用意した
のは,データを格納する容れ物であってデータそのものではない.クラスという
のは,型のことである(最初にもそう述べたが).書誌データが入力されたものを
インスタンス(実体)という.クラスは,もっと抽象的でどんなデータセットが必
要か定義したものであり,もっと具体的にデータが入ったものがインスタンスで
ある.クラスの中のそれぞれはオブジェクトといわれる.クラスの中のオブジェ
クトにアクセスするにはドット演算子「.」を利用する.
型と演算がわかれば,次は制御構文だ.プログラムには繰り返しや,条件分岐や
ループなとの制御する構文が必要である.
そうでないとプログラムは一直線の道しか走れないことになる.
if文は条件分岐を制御する構文である.ifで条件を提示し,
条件に適う時の処理をブロックインデントされた範囲に記述する.
elseで,条件と違った時の挙動をブロックインデントで記述する.
たとえば,
#! /usr/bin/env python
i = raw_input()
if i % 2 == 0:
print "even number"
else:
print "odd number"
というプログラムがあったとする.raw_input()函数で,ユーザーから入
力を促し,iに代入する.iを2で徐したものの剰余を求め,それが0なら偶
数(even), そうでないなら奇数(odd)という判断をしている.==は比較演
算子で,等しければBoolean 1を返し,そうでなければ0を返す(代入演算子=とは違うことに注目されたい).一見うまくいっているように見えるが,この
プログラムには落し穴があって,iが整数以外のものの場合でも elseに落
ちて,「奇数である」と云われてしまう.おかしな挙動をすることはエラーより
も始末がわるい.これはいろいろ修正方法があるが,たとえば下記のように修正
できる.
#! /usr/bin/env python
i = raw_input()
if i % 2 == 0:
print "even number"
if i % 2 == 1:
print "odd number"
この場合,iが整数以外のものだと,なにもしない.なにもしないのもさみしいので,「整数ではありませんよ」というメッセージを出す文を付加する.
#! /usr/bin/env python
i = raw_input()
if i % 2 == 0:
print "even number"
if i % 2 == 1:
print "odd number"
else:
print "not integer"
しかし,この文章は間違った動作をする.iが偶数の時,
最初のif i % 2 == 0:で,``even number''とprintされる.
ここまではよい.しかし,
次のif i % 2 ==1:でも条件判断され,
当然ながら偽となるので,elseに落ちてしまい,
``not integer''とprintされてしまう.
それを回避するためにはif文をネスト(入れ子)にすることができる.
#! /usr/bin/env python
i = raw_input()
if i % 2 == 0:
print "even number"
else:
if i % 2 == 1:
print "odd number"
else:
print "not integer"
この文章では,2回目のifにかかるのは,一回目のifが偽の時に限
るので,偶数がもう一度2回目のifにかかって,
else: print "not integer"に陥いることを避けられる.
しかし,条件分岐をネストすることの最大の問題点は,条件を重ねるごとにインデントが深くなり,可読性が落ちることである.
Pythonにはネストによるインデントの累重を避けるために,elif(=else
ifの略)という条件分岐構造が準備されている.これは,前件の条件に対して偽
の時に,新たな条件を提示して,真偽を問うものである.
#! /usr/bin/env python
i = raw_input()
if i % 2 == 0:
print "even number"
elif i % 2 == 1:
print "odd number"
else:
print "not integer"
これで随分とすっきりとした.条件構文のif, elif, elseの
三者ともインデントが同じ位置にある(全部インデントなし)ことに注目されたい.
複数の条件式はBool式を用いて結合できる.たとえば,
if i % 2 == 0:
if i % 3 == 0 :
print "6の倍数です"
というコードがあったとしよう.これも複雑にネストしているが,2つの条件式を
and演算子で結合して,
if (i % 2 == 0) and (i % 3 == 0):
print "6の倍数です"
のように簡潔に記述できる.もちろんor演算子も使える,たとえば,下記
のようになる.
if (uname = "BSD") or (uname = "Unix"):
print "Unix使いなら自分で出来るでせう!"
else:
print "本ソフトは対応しておりません."
ここでunameはOSの名前を指すユーザー定義の変数とする.
or演算子で注意しなければいけないのは,計算機上のor演算子は数
学の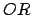 と異なり条件式を最後まで読まない.条件を判断できるところまで読む
「短絡評価」という処理を行っている.これはPythonだけに限らず,ほとんどの
プログラム言語の実装である.たとえば,上の例なら,BSD使いだと判明した時
点で,「Unix使いなら...」となる.
と異なり条件式を最後まで読まない.条件を判断できるところまで読む
「短絡評価」という処理を行っている.これはPythonだけに限らず,ほとんどの
プログラム言語の実装である.たとえば,上の例なら,BSD使いだと判明した時
点で,「Unix使いなら...」となる.
forループは,インデックスとなる変数に逐次リストの要素を代入してい
く制御構文である.書くと難しいが,たとえば,前にこんなプログラムがあった.
#! /usr/bin/env python
message = "Hello, World!"
print message
print message
print message
これはforループを使うと
#! /usr/bin/env python
message = "Hello, World!"
for i in range(1,4):
print message
となる.range()函数は,最初の引数から,[次の引数-1]までの数
の列(リスト)を返す. この例では,[1,2,3]である.このリストの要素が
前から順番にiに代入され,インデントされた文において実行される.
Pythonでは制御構文のブロックはインデントで範囲づけられることを思い出して
ほしい.また,forの文末に:が必要なことも忘れないでほしい.こ
れは次のインデントされたブロックがforの動作部であることを示す徴で
ある.ブロックが複数の文ではなく,一つの文からなる時は,同じ行に記述して
もよい(当然,インデントはなし).
#! /usr/bin/env python
message = "Hello, World!"
for i in range(1,4): print message
この例では,全然インデックスのiを使用していないのでさみしいが,動
作部には普通,iに関係づけられる処理を記述する.たとえば,ある数列
の挙動を見たいとしよう.次の例はFibonacci数列と呼ばれる数列である.
#! /usr/bin/env python
old=0
new=1
for i in range(1,30):
print "%2d %6d" % (i,old)
old,new = new, new+old
この例では,何番目かと,i番目の時の数列の値が示される.なお,桁数
を揃えるためにprint文とprintf()の使い方をしている.
forループは大変便利なのだが,欠点が一つある.それは,最初に代入す
る候補を全て列挙(リストアップ!)してあげなければいけないことだ.forループに入る前に,予めリストが決定すればよいが,いつループが終了する
か,やってみないとわからないものもある.たとえば,ファイルから一行づつ読
みとって処理するループの場合,いつ最後の行になるかは,ファイルを最後まで
読みとらなければわからない.そのような時に重宝するのがwhileループ
である.最初の文例はwhileループでも処理できて,下記のようになる.
#! env python
message = "Hello, World!"
i = 1 # iを定義・初期化する.
while i <= 3 :
print message
i = i + 1 # iをインクリメントすることを忘れずに
# (さもなくば無限ループ)
for文と同様に,「:」とブロックインデントが必要なことに注意し
てほしい.
for文と同じく,Fibonacci数列を演算させてみる.次のwhile文
では,継続条件を値が99999以下としている.数列の値が99999の間は演算を続行
し,99999を越えるとwhile文が終了する.
#! /usr/bin/env python
old=0
new=1
i=1
while old < 99999 :
print "%2d %6d" % (i,old)
old,new = new, new+old
i = i + 1
これは次のような書き方もできる.
#! /usr/bin/env python
old=0
new=1
i=1
while 1 :
if old > 99999: break
print "%2d %6d" % (i,old)
old,new = new, new+old
i = i + 1
while 1は常に正しいから,これは無限ループとなる.それを
break文で中断させるのである.中断条件をifで指定している.
Pythonの特徴の一つがブロックインデント(インデントを用いてブロックを示す)
である.他の言語ではブロックを示すのに,BEGIN...END や
\begin{...}...\end{...} あるいは単に...などのよう
にブロックのサインを置いている.サイン式のブロック表記法では,レイアウト
に関係なく作文できる自由度がある反面,読みにくいコードも簡単に書けてしま
う.ブロックインデントは,レイアウトを強制する点で,プログラマーの自由度
を奪っているが,しかし,そのレイアウトはプログラムの論理構造を反映してい
るため,見通しのよい作文を可能にする利点がある.たとえば,たくさんの構文
をネスト(入れ子)にすることが稀にある.たとえば,次のように.
for i in ....:
print message
....
if text == "...":
....
while j => 255:
....
print ....
if something :
....
kakuno unzarisimasu
if demo madamada tuduku...
korede owari to omoikiya
if totyude tobikyu sitarisite
print "mou unzari"
これは可読性に劣る.だから,Pythonはダメだということになるかもしれないが,
ダメなのはコードの方である.ネストしすぎて画面からはみ出るか九十九折りに
なるようなコードは構造が間違っているから,最初から考えなおしたほうがよい,
とLinus氏も云っている.Pythonはフォーマットを強制することにより,複雑(・
怪奇)な文章を書くことを抑制している.なおPythonのインデントについて幅の
制約はない.たいていタブ一文字か,スペース3〜6文字が多いようである.原理
的にはスペース一文字でも十分である.
函数は,一連の手続きをセットにしておいて,あとから自由に呼び出して結果を
得るための方法である.函数には引数を渡すことができ,外部からは数学の函数
と同じように扱うことができる.
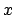 が引数である.引数の値をいろいろ変えることができ,それにより得られる
結果
が引数である.引数の値をいろいろ変えることができ,それにより得られる
結果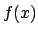 も異なる.使い方はこれまでにモジュールの使い方のところで説明し
た.
も異なる.使い方はこれまでにモジュールの使い方のところで説明し
た.
どうして函数をいうものが必要なのか.それは第一に車輪を二回発明しないため,
第二に,人間の思考の整理のためである.第一の理由は,同じことを何回も行う
場合,その都度,それを記載するのはバカげている.手続きをまとめておいて,
その都度それを呼び出したのほうが紙面(行数?)の節約にもなるし,あとから別
のプログラムで,その函数を呼び出すことができれば,別のプログラムで同じこ
とを再開発するムダを節約できる.第二の理由は,作業のほとんどは--プログ
ラムに限らず--いくつかのステップに分解できる.ステップに分解できるから
といって必ずしも分解する必要はないが,ステップに分解した方が,その作業に
対する理解が早まるし深まる.なぜなら,全部を一つして一度に捉えるのは大変
だが,分割可能なステップに分解して,それぞれを理解してあとで総合するほう
が理解がたやすいためである.また,作業全部を一枚岩として捉えるよりも,ス
テップに分割したほうが作業の隅々まで深く理解できる.
例としてFibonacci数列を函数として扱えるようにしたものをこれから示す.最
初は,引数を越えない値を出力する函数である.
#! /usr/bin/env python
import sys
def fibonacci(n):
"""caliculate a Fibonaccian series upto argument"""
old=0
new=1
i=1
while old < int(n) :
print "%3d %6d" % (i,old)
old,new = new, new+old
i = i + 1
arg=sys.argv[1]
fibonacci(arg)
print "Fibonaccian series upto",arg
次に,引数番目までのFibonacci数列を出力する函数である.
#! /usr/bin/env python
import sys
def fibonaccian(m):
"""caliculate a Fibonaccian series upto argument"""
old=0
new=1
i=1
while i <= int(m):
print "%3d %6d" % (i,old)
old,new = new, new+old
i = i + 1
arg=sys.argv[1]
fibonaccian(arg)
print "Fibonaccian series for",arg
最初のdefにより函数の定義を与へる.まづ,函数の名前を定義し,
()の中に,temporaryな引数の名前を記す必要がある.引数は函数のブロッ
クの中だけでしか通用しないもので,ブロックの外では未定義の変数となる.ま
た,ブロックの最初には函数の説明文を文字列として与えることができる.これ
をドキュメント文字列と呼ぶ.
ドキュメント文字列は別に書かなくともよいが,二点から記述することをお勧め
したい.第一に,腕の立つプログラマーは--どの言語でも--その函数とは何か
を函数の定義の近辺でコメントする.これはreadabilityを向上させるの貢献し
ている.Pythonのドキュメント文字列はこのよい実装となっており,よいプログ
ラミングの習慣づけの点からお勧めしたい.第二に,ドキュメンテト文字
列を抽出加工して,マニュアルや技術文書を作成するツールがある.これは
Knuth・有澤 (1994)が文芸的プログラミングと提唱した考え方で,別途マニュアル
を作成する手間をはぶけるメリットがある.プログラムが完成してからマニュア
ルを書くとマニュアルの内容がプログラムから遊離しがちである.また,マニュ
アルを書くために再度プログラムを読みなおすよりは,プログラムを書いている
時にマニュアルを記述するほうが作業効率が高い.対話的にドキュメント文字列
を出力されるには,
>>> def documant():
... """This function is only for documentation string,
... which is also called docstring."""
... pass
>>> document.__doc__
This function is only for documentation string,
which is also called docstring.
のように,__doc__とする.このやり方はオブジェクト指向の設計による
ものなので,説明は後述する.passはなにもしないコマンドである.函
数の中身が空だと都合がわるいので置いてある.
上記のFibonaccian数例の例では,函数を実行すると,print文で数列を出
力する.函数には戻り値という概念がある.
の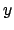 が戻り値である.この場合の戻り値はNoneである.Pythonでは戻り
値が定義されていない場合はNoneになる.戻り値の指定には,return文を用いる.上述のFibonnaccian数列を出力する函数でも数列そのものを
戻り値にすることができる.
が戻り値である.この場合の戻り値はNoneである.Pythonでは戻り
値が定義されていない場合はNoneになる.戻り値の指定には,return文を用いる.上述のFibonnaccian数列を出力する函数でも数列そのものを
戻り値にすることができる.
#! /usr/bin/env python
import sys
def fibonaccians(m):
"""caliculate a Fibonaccian series upto argument"""
old=0
new=1
i=1
fibo=[]
while i <= int(m):
fibo.append(old)
old,new = new, new+old
i = i + 1
return fibo
arg=sys.argv[1]
i=1
for fibonac in fibonaccians(arg):
print "%3d %6d" % (i,fibonac)
i = i + 1
return文で注意したいことは,returnの後に何を書いても,コード
は実行されない.このようなコードをdead codeと呼ぶ.
函数は手続きのまとまりを分離し,再利用可能な形態に整理するだけでも十分有
用であるが,函数のパワーはそれだけではない.函数を再帰的(自分で自分自身
を呼び出すこと)により,通常ではとても長いあるいは記述不能な処理を実現す
ることができる.再帰的(recursive)定義に似た論理学術語に循環的(circular)
定義があるが,真実の循環はまったく役に立たない.
愚かとは,愚かものに対する形容詞である.
これでは愚かとはなにかについての情報はなにも得られない.
適切に判断します.なにが適切かは,適切に判断します.
これも同じで,なにが適切か,ちっともわからない.
業績がないから無能である.なぜなら無能でなければ業績がある筈だからである.
これは循環論法と呼ばれる論理的錯誤のひとつで,前提の正しさを証明するため
に,結論をもちだしている.これでは論証したことにはならない.
再帰的定義は,
定義のなかに,定義されるものを参照している定義
のことである.
the definition which contains a reference to the thing being defined.
再帰は循環を含むこともあるが,役に立つ再帰的定義はこれとは全く違っ
て,定義により,定義前より問題が解決の方向に多少なりとも進んでいる.たと
えば僅かな前進であっても,それを繰り返すことにより解決に至る場合が数学的
問題にはよくある.例として,階乗(連乗積,factorial)を示す.階乗は
のような数のことで,たとえば
これを漸化式で書くと,
となる.階乗の定義に階乗を使っている.だから,これは再帰的定義である.こ
れをPythonの函数の再帰的定義を利用して解いてみよう.最初に函数をモジュー
ルの形で定義する.ファイル名をfactorial.pyとする.
factorial.py
def factorial(n):
if n==1: return 1
else:
return n*factorial(n-1)
これを使用するには下記のようにする.
>>> import factorial
>>> print factorial(1)
1
>>> print factorial(2)
2
>>> print factorial(3)
6
>>> print factorial(4)
24
>>> print factorial(5)
120
>>> print factorial(6)
720
>>> print factorial(7)
5040
最初のimport factorialでロードする.拡張子の.pyは不要である
ことに注意されたい.コアの部分から説明する.elseでnの時,
factorial(n-1)を呼び出している.つまり,再度,この函数が呼び出され
るわけである,ただし,n-1として呼び出されるので,少しは問題が単純
化した.factorial(n-1)は,factorial(n-2)を呼び出すわけである.
こうして連鎖的に函数が呼び出され,いつかn==1の時になる.その時は最
初のif式でn==1に落ち,再帰的呼び出しが終了する.
現在のプログラムは複雑であるから,全てに目を通してそれぞれの動作が正しい
ことを確認していては日が暮れてしまう.自分が書いたプログラムであってもそ
うである.自分が書いたスクリプトは短かいから全て理解できるなどと思っては
ならない.たとえば printがどうやって動いているか,諸君は知っている
か?,たとえば,諸君はハードディスクの円板からどうやって情報を取り出して
いるか自分で作れる程度に知っているか? CPUがどうやって演算をしているか諸
君は知っているか?それを知らないで理解していると思ってはいけない.理解す
るというのは大変なことなのである.それは大変だから,ある程度の確認
作業が済んだらできているものと見倣すわけである.これをLeap of Faithと呼
ぶ.Leap of Faithは哲学・究理学の概念であるから最初に科学理論(特に物理法
則)で説明する.たとえば万有引力の法則を全てのケースについてテストするこ
とはできない.あっちのリンゴとこっちのリンゴは同じリンゴと云えば同じリン
ゴであるが,同時に違うリンゴでもある.それは読者諸子と私は同じ人間である
が,同時に違う人間であるのと同じである.あっちのリンゴで成り立つからといっ
てこっちのリンゴで成り立つ保証はない.しかし,いちいちテストしていては時
間が足りないし,学問が進歩しない.生きている時間は限られている.永遠に未
来が続くのは若者だけだ.全てを検証する時間はない.そこで,あっちのリンゴ
もこっちのリンゴも同じものを見倣すのである.
計算機も同じである.たとえば,上のFibonacci函数をいくつかのケースでテス
トしたら,その函数が「できた」ものと見倣すわけである.これは科学理論と似
ている.これをLeap of Faithと呼ぶ.これは少し奇妙である.Fibonacci函数は
とりあえずできたかもしれないが,まだFibonacci函数を用いる本体のプログラ
ムは完成していない.本体が完成していないのに,「できた」というのはどうい
うことだろう?それこそがLeap of Faithと呼ばれる理由である.
ここで,テストや確認作業をどうするかが重要である.自分に都合のよい引数だ
け与へていては,テストにならない.しかし,実際にはありえない引数を与へて
函数が動かないというのは過剰テストである.
しかし,たとえテストにパスしても,誰が御墨付を与へようとも,もし,プログ
ラムが変な動作をしたならば,それは反証されたということである.もし,
その原因を知りたければ,コードやそこから生成されたバイナリー,バイナリー
が実行されるところと,どこまでも掘り下げていって追求する必要がある.たと
えば,Pythonのスクリプトが変なところで,segmantation faultで落ちたとする.
スクリプトだけ見ていてもどうしても原因がつきとめられない時は,PythonのC
言語で記述されたコード自身を見なければいけない.そして,C言語がどうやっ
て演算しているのか,バイナリーにはどういう命令がコードされているか追求す
るのである.もちろん,それは大変手間がかかる上に,技術も要するので,必要
に応じてである.学問的追求も大事だが,費用対効果や,十全の法則(プログラ
ムはその作業に対して十全に機能すれば完璧でなくてもよい.)を忘れてはいけ
ない.
この例は科学理論で云へば,万有引力の法則の予言する結果を微妙に結果が異な
る場合,例外とか特殊事情・観測機器の誤差でそうなったと無視することもでき
るが,それが深刻なものや無視できないものである場合,とことん掘り下げて追
求する必要がある.前者はこれは費用対効果や十全の法則に従った方針でLeap
of Faithである.後者はそのLeap of Faithが破綻した後の方針で,学究的態度
といえる.それにより,たとえば,重力により空間が歪むため,単純に万有引力
は成り立たないということが明らかになったりする.
棒取りしているようなデータストリームでは,しばしばデータを間引く必要が生
じる.たとえば,一秒に1回サンプリングされたデータがあるが,実際に解析に
使用するのは,10秒に1回でいいということがある2.3.データ
は一回につき一行づつ増えていくとしよう.これを10回に1回だけ抽出したいが,
最初と最後のデータも抽出したい.その要求を満すスクリプトは下記のとおりで
ある.
skip.py
#! /usr/bin/python
import fileinput
interval = 10
for line in fileinput.input():
shot = fileinput.filelineno()
if shot == 1 :
print line,
elif shot % interval == 0:
print line,
print line,
3行目にinterval変数を設定して,skipする間隔を後から変えやすくして
いる.たとえば,間隔を100にしたければintervalに100を代入すればよ
い.中途半端な256という数字でも大丈夫だ.ただし,間引くかどうかの判定に
割切れるかどうかを使っているので,intervalは整数でなければいけな
い.
次にforループで fileinputモジュールのinput()メソッ
ド(函数)を用いてline 変数に一行づつ行の内容を代入している.
shotは行数を示す変数である.fileinputモジュールには
filelineno()という函数が行数を示すので,それを代入している.スク
リプトの7行目では,1行目かどうかをテストし,1行目ならは,行のラインをプ
リントする命令を与えている.line,と最後にコンマがつくのは,
line変数は改行を含めた行の内容が格納されているためである.
print文は改行を付加してプリントするので,print lineとする
と二重に改行がプリントされることになる.そこでコンマを置いてprint
文の改行を抑制しているのである.
次に,インデックス番号が100増えるごとに間引くスクリプトを書いてみやう.
ただし,データにはクセがある.単純なデータなら上のスクリプトのintervalを100にすればいいが,下記のようなデータだとさふはいかない.
GPS data
134.7313 33.155 -25
134.7256 33.168 35
134.7187 33.1833 125
134.7085 33.2163 275
134.7015 33.2512 425
134.6957 33.2788 545
この例は1982年に取得したある位置情報をGMTで用いるxyのデータにしたもので
ある.位置データは電波測量(ロラン)で取得された古い記録なので,データには
抜けがある.しかも,インデックス番号は最初が1ではなく,負の数になってい
る.また,インデックスの値がとびとびになっていて,100行送っても,インデッ
クス番号は100ではない.どうすればいいか? まず最初にデータを補完して,一
行につきインデックスが1増えるデータに変換する.そして100行おきに間引くこ
とになる.かなり複雑になる.今回はデータの補完だけすることにして,どうす
ればよいか考へてもらいたい(回答例は後の項目にある).
データの再フォーマットはしばしば必要になる.たとえば,Tiff形式の画像ファ
イルをホームページに掲載するためにJpeg形式に変換する,というのはよくある
作業である.
ここでは,もっとも簡単なテキストデータのフォーマットの変換を紹介する.もっ
とも簡単なフォーマットの変換は列の入れ換えである.第1列に入っているデー
タを3列目に,2列目を5列目に...のように,列の順番を入れ換える作業であ
る.次に簡単な変換の一つとして,列の区切りを変更する変換を紹介する.たと
えば,タブ区切りのデータを固定長のスペース区切りに変更することである.ま
た,列に操作を加へて新しい列を作成することも簡単な変換と云える.たとえば,
度分で表示された緯度経度情報を度だけで示す変換や,その逆,あるいは華氏温度
の摂氏温度への変換などである.
例として,度(degree)で示されたxyデータを,固定長のデータに変換するスクリ
プトを示す.
#! /usr/bin/env python
import string
import sys
import fileinput
linename = sys.argv[1]
linename = string.replace(linename,".xy","")
basename = linename[0:4]
name = basename+"-"+linename
for line in fileinput.input():
line=line.strip().split()
shot = int(line[2])
lon = float(line[0])
londd = int(lon)
lonm = (lon-londd)*60
lonmm = int(lonm)
lons = (lonm - lonmm)*60
lonss = int(lons)
lonsss = int((lons-lonss)*100)
lat = float(line[1])
latdd = int(lat)
latm = (lat-latdd)*60
latmm = int(latm)
lats = (latm - latmm)*60
latss = int(lats)
latsss = int((lats-latss)*100)
print " %-17s %6d%02d%02d%02d.%02dN%03d%02d%02d.%02dE" %(
name,shot,
latdd,latmm,latss,latsss,
londd,lonmm,lonss,lonsss)
以下,未稿
華氏(Fahrenheit)は水の凝固点(氷点)を32 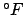 とし,沸点を212
とし,間を180分割した温度である2.4.換算式は以下のよう
になる.
とし,沸点を212
とし,間を180分割した温度である2.4.換算式は以下のよう
になる.
やや,ややこしい変換にファイル名をデータセットに付加する変換や,別に用意
したリストから条件を決めてどれか選んでデータセットに付加する変換がある.
前者の例として,複数の測線のxyデータをダイジェストして1ファイルにしたい
場合がある.後者の例として,住所録から住所から郵便番号をリストから選択し
て,データセットに付加する作業がある.
前者の例.
#! /usr/bin/env python
# per 10 shots discount
import fileinput
import sys, re
for line in fileinput.input():
line=line.strip().split()
shot =fileinput.filelineno()
lon = float(line[0])
lat = float(line[1])
name = sys.argv[1]
name = re.sub(r'\.xy','',name)
printform=str(name)+","+str(shot)+","+str(lat)+","+str(lon)
if shot == 1 :
print printform
if float(shot) /10 - (shot/10) == 0:
print printform
# print printform
後者の例.
ディクショナリ(ハッシュ)を使う.住所を引数とすれば,郵便番号が戻り値とな
るようなディクショナリ(文字通りディクショナリ)を作ればよい.
未稿
Multi-narrow beam echosounder(MBES)のデータストリームはASCIIであるが,これまで
述べたデータ構造と比べて格段に複雑な構造をしている.
未稿
MBESのデータ構造はASCIIの体裁をしているものの,一般的なBinaryデータの構
造に酷似している.MBESで学んだことを生かしてBinary fileの加工に挑戦する.
未稿
時間はやっかいだ2.5.時間は10進法ではな
い.まず,60進法がある.60秒が1分,60分が1時間.しかし,24時間で1日だか
ら,これは24進法だ.だいたい30日で1ヶ月だから,ここは30進法と云えなくも
ないが,28日の月もあるし,31日の月もある.定数ではない.では,日から直接
年を出そう.この考え型を通年日といい,一年の最初からの通算日で,日を表現
する.一年は365日だから,365進法といっていいだろうか.これくらいならまだ
なんとかなりそうである.しかし,そうは問屋が卸さない.閏年といって,一日
余分がある年が四年に1回ある.しかも,100年に1回(100の倍数の年)は閏年で
ある筈の年が閏年でなくなる...かつ,その閏年であるはづだが100年に1回
の閏年ではなくなる年の400年に1回(400の倍数の年)は,閏年になる.これを計
算機で処理させるには...頭いたくなってきた2.6.
ここで登場するのがtime()函数である.これはUnixのCの標準ライブラリの一つ
で,上記のややこしい計算や表示形式の変更などを司ってくれる.Pythonでは,
datetimeモジュールというものがあって,それが綜合的に時間に関する操作(表
示形式の変換を含む)を受けもっている.しかし,ここでは自分たちが使う時間
の形式変換を自分たちの手で実装しよう2.7.
最初に,計算機はどのように時間を処理しているか理解する必要がある.Unixの
time()函数は内部では,あるエポックからの通算秒で処理している.
1972/12/24/20:45:12
を全秒に変換するプログラムと,逆に与えられた全秒表記を上記のような表記に
変換するプログラムがあると,いろいろと便利だ.
未稿
この例は,あるpositioning データを加工して,GMTのtrackファイルに変換する
プログラムである.
まづ,track fileは
2006 6967 12-Sept
2006/09/12/09:22:08 41.85026603 142.807218358 NaN NaN NaN 1
2006/09/12/09:22:14 41.850148225 142.807194888 NaN NaN NaN 2
2006/09/12/09:22:20 41.850030615 142.80716821 NaN NaN NaN 3
2006/09/12/09:22:26 41.8499192517 142.807139283 NaN NaN NaN 4
2006/09/12/09:22:32 41.8498005933 142.807110375 NaN NaN NaN 5
2006/09/12/09:22:38 41.8496752567 142.80709425 NaN NaN NaN 6
2006/09/12/09:22:44 41.8495616883 142.807060533 NaN NaN NaN 7
のようになっている.一行目がヘッダーに充当されており,航海年,データの行
数(ファイルの行数ではないことに注意),トラック名(この例では英国式の月日
で示している)がスペース区切で記入されている.2行目以降がデータ領域で,最
初のブロックは年月日時分秒,緯度,経度,重力(この例ではデータがない[NaN]
が,mgalで記述),磁力(この例ではNaNだが,mTで記述),水深(この例ではNaNだ
がmで記述),インデックス番号(これはGMTの定義にはない.音波探査独特の仕様)
が含まれている.
一方,今回のpositioningデータは米国Geometrics社のCNTという探鉱器で
収録されるGPSデータである.そのフォーマットは
1, Tuesday, September 12, 2006 at \
09:22:08, 514105, 150660, $GPGGA,092208.00,\
4151.0159618,N,14248.4331015,E,2,08,1.1,-1.78,M,32.40,M,4.0,0678*6A
2, Tuesday, September 12, 2006 at \
09:22:14, 514105, 150660, $GPGGA,092214.00,\
4151.0088935,N,14248.4316933,E,2,09,1.0,-1.29,M,32.40,M,4.0,0678*66
3, Tuesday, September 12, 2006 at \
09:22:20, 514105, 150660, $GPGGA,092220.00,\
4151.0018369,N,14248.4300926,E,2,09,1.0,-2.05,M,32.40,M,2.8,0678*6B
4, Tuesday, September 12, 2006 at \
09:22:26, 514105, 150659, $GPGGA,092226.00,\
4150.9951551,N,14248.4283570,E,2,09,1.0,-1.69,M,32.40,M,4.0,0678*6E
5, Tuesday, September 12, 2006 at \
09:22:32, 514105, 150659, $GPGGA,092232.00,\
4150.9880356,N,14248.4266225,E,2,09,1.0,-1.64,M,32.40,M,4.0,0678*66
となっている.ただし,行が長いため継続行を\で示している.
これは非常に単純で,ショット番号(インデックス番号)やアメリカ式の日時を並
べ,GPSのシリアルセンテンスが張り付いているだけである(この例ではGPGGA形
式だが受信機によって入力されるセンテンスの形式は異なる).
これをtrack fileに変換するスクリプトは下記のとおりである.
#! /usr/local/bin/python
import fileinput
import re
year = 1973
month = ""
day = ""
daymonth = ""
lines = 0
hms = ""
monthc2n ={
'January':'01',
'February':'02',
'March':'03',
'April':'04',
'May':'05',
'June':'06',
'July':'07',
'August':'08',
'September':'09',
'October':'10',
'November':'11',
'December':'12'
}
for line in fileinput.input():
if lines == 1:
line=line.strip().replace(","," ").split()
year=str(line[4])
month=str(line[2])
day=str(line[3])
# daymonth=day+"-"+month[0:4]
daymonth=monthc2n[month]+day
lines = lines + 1
print year,lines,daymonth
for line in fileinput.input():
line = line.strip().replace(","," ").split()
line[13] = float(line[13])
line[11] = float(line[11])
lon = int(line[13]/100)+(line[13]-100*int(line[13]/100))/60
lat = int(line[11]/100)+(line[11]-100*int(line[11]/100))/60
#shot = line[0]
shot = fileinput.filelineno()
year = str(line[4])
month = monthc2n[line[2]]
day = str(line[3])
hms = str(line[6])
print year+"/"+month+"/"+day+"/"+hms,lat,lon,"NaN NaN NaN",shot
注意しなければいけないことは,入力されるGPSがセンテンスが異なれば,スク
リプトも改造しなければいけないことである.
情況とは常に変化し得るものである.メンテナンスできなればソフトは動かない
も同然である(Weinberg, 1979).
飛び飛びにしかないデータを繋いで連続的なデータセットにしたい時はよくある.
たとえば,不定期に飛び飛びなデータから一定間隔のデータを作成する場合には,
一旦,連続的なデータにしてから一定間隔ごとに間引く方法が考へられる.
今回は,飛び飛びしかないデータを補完する方法を紹介する.例として前述した
GPSデータをとりあげる.
GPS data
134.7313 33.155 -25
134.7256 33.168 35
134.7187 33.1833 125
134.7085 33.2163 275
134.7015 33.2512 425
134.6957 33.2788 545
これをインデックス番号が1づつ増えるようなデータに変換するためのスクリプ
トは下記のとおりである.
#! /usr/pkg/bin/python
import fileinput
counter = 0
for linea in fileinput.input():
linea = linea.strip().split()
if fileinput.filelineno() == 1:
lineb = linea
prln = linea
if int(prln[2]) > 0:
print prln[0],prln[1],prln[2]
if lineb != linea :
counter = 0
diffshot = int(linea[2]) - int(lineb[2])
diffshot = int(abs(diffshot) -1)
diffx = float(linea[0]) - float(lineb[0])
diffy = float(linea[1]) - float(lineb[1])
while counter < diffshot:
counter = counter + 1
linec[0] = float(lineb[0]) + diffx * counter / diffshot
linec[1] = float(lineb[1]) + diffy * counter / diffshot
linec[2] = int(lineb[2]) + counter
prln = linec
print prln[0],prln[1],prln[2]
prln = linea
if int(prln[2]) > 0:
print prln[0],prln[1],prln[2]
lineb = linea
このスクリプトでは,インデックスが0より大きくないと出力しないことに読者
はお気づきだろうか?
英語の読みやすさは,我々のような非英語母語者だけでなく,英語話者にとって
も重要である.英語は柔軟な言語であるがためにかえって奇妙な文章が容易に生
み出されてしまう.英語の読みやすさ(readability)を定量化するプログラムが
あれば,よい作文に貢献するに違いない.
readabilityにはいくつかのindex(指標)がある.たとえば,
- 文に対する単語の数(つまり,文の長さ)
- 長い文は読みにくいが,短かい
文は読みやすい(ただし,あまり短文ばかりだと`ぶっきらぼう'あるいは幼稚な
印象を与へたり,コンテキストが断片化して思考の流れを防げる弊害がある).
英語では屡,wps(words per sentence), ASL(average sentence length)で測ら
れる.一般的にはA4, 10.5pt程度の原稿で3行以上になる文は長文とされる.単
語の長さによって3行になる単語数は異なるが,だいたい30-40語を目安として,
長文かそうでないかと判定することが多い.
- 段落を構成する文の数(つまり,段落の長さ)
- 概念としては文の長さと同
じ.延々と続く段落は読みにくい.ドイツ語で3ページずっと同じ段落の文章を
読んだことがあるが,大変読みにくかった.英語では近代英語まではそういうス
タイルもあったが,現代英語では許容されない(ドイツ語では許されるらしい).
一般的には段落は3-5文程度で構成されるのが望ましいとされる.10文を越える
と長すぎと診断されることが多い.
- シラブル(音節)の数(量比)
- 日本語では文の長さを文字数で勘定する.伝
統的には原稿用紙400字何枚という風に原稿の長さを文字数で勘定してきた.し
かし,英語では文字数よりも単語数で文の長さを規定する.単語数で規定する場
合には長い単語も短かい単語も同じ一単語として勘定してしまうために単語数が
少ないけれど,各単語が長いために読みにくい文というのがありえる.また,ア
ルファベットは不完全な表音文字で一字一音ではないために文字数で単語の長さ
を勘定すると音韻としての単語の長さと齟齬が生じる(たとえばtは1字,thは2字
だが,音韻としては[t]と[
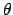 ]とどちらも一音).そのため,文・
単語の長さを正確に定量化するためには音節の数を基準にする必要がある.
英語では, ASW(average syllables per words)で示す.
]とどちらも一音).そのため,文・
単語の長さを正確に定量化するためには音節の数を基準にする必要がある.
英語では, ASW(average syllables per words)で示す.
- 抽象語の数(量比)
- 抽象語は理解しにくい.抽象語とは見たり触ったりで
きないもの全てを指す.ただし,言語そのものが抽象性をもっているので,なに
が抽象語かを巡って,しばしば線引問題になる.実際,抽象語の定義は分野依存
性が強いので,分野ごとに抽象語のリストを用意する必要がある.抽象語の量比
をパーセントで示したものは,Cohen's Cloudiness Countとも呼ばれる
(Mannuals, 1984).抽象語は煙に巻くのでcloudinessである.科学論文では抽象語
は3-6%に留めることが望ましい.
- 受動態の数(量比)
- 受動態の文章は理解しにくい.
- 否定語の数(量比)
- 否定語の多い文章は理解しにくい.二重否定,三重否
定などは,科学および非形式論理学の文章においては可能な限り避けなければい
けない.
- 二次統計量・指数
- これは上記一次統計量から算術的に導かれる指数で,
各要素を綜合的に(ある重みづけをつけて=恣意的に)判断して,readabilityを人
間にわかりやすく表現したものである.代表的なものにFlesch Grade
Level/Flesch Score(Flesch, 1976)やfog index(Gunning, 1973)と呼ばれる指数があ
る.たとえば,Flesch Scoreでは,科学論文は40-50が適当で,70以上だと童話
なみの読みやすさとされる.人の論文の要旨をいくつか代入してみたが,だいた
い20-30が多い.それでもそんなに難しく感じないので40-50は努力目標だろう.
また,Flesch Grade Levelでは文章の可読性を米国の学校の学年で表現する.
Levelに6を足せば年齢になる.一般的な文章では8が適当とされる.科学論文は
12程度が望ましいとあるが,大学院生程度=18までは許されるであらう.いろい
ろ文章を代入してみると,Levelが30を越えるものも結構多い.
- 視点の一貫性
- 視点がコロコロ変わる文章が読みにくい.
与へられたテキスト(ASCII)から,上記のindexを計算して,readabilityを報告
するプログラムを作成した.ただし,視点の一貫性を判定するプログラムは,統
語論解析が必要で,この本の手にあまるので取りあつかわない.syllableの認定
も,英語音韻学の知識が必要だが,これは統語論よりは簡単なので,本稿で取り
あつかう.二次統計量は一次統計量から自動的に算定される.
TEXのソースファイルは dvi2ttyプログラムを用いて,ASCIIに変換する.
この手法は TEX固有の命令,特に数式が多いと,判定プログラムがうまく機能
しないことが予想されるが,数式が多い文章は概して読みやすい(数式の意味が
わかるならば,の話).一方,TEXのソースから,TEX命令を適当なASCIIに置
きかえる函数を容易するのは面倒であるし,それはdvi2ttyのすべき仕事と考え
て,現時点ではTEXのソースにはdvi2tty filteringで対応する
2.8.
私は,次に述べるプログラムを用いて,論文のreadabilityを各subsectionごと
に判定し,あまりよいスコアでないところは訂正してから投稿している.
行数が多すぎるため,またまた推敲を経ていないスパゲッティコードなので未掲
載.
未稿
未稿
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
![$X(n)[i] = X(n-1)[i]+X(n-1)[i-1]$](img25.png)
未稿
オブジェクトのパワー
例として下記のようなクラスを定義する.
class Uisge:
""" This is a class of whiskies."""
def __init__(self,
Name, Distill, Land, Age="NaN",
Price="NaN",Type="Blended", Note="NaN"):
self.Name = Name
self.Distill = Distill
self.Age = Age
self.Land = Land
self.Price = Price
self.Type = Type
self.Note = Note
def printHTML(self):
print "<dt>"+self.Name+"</dt>"+\
"<dd>"+\
self.Distill+\
"; Age: "+self.Age+"; "+self.Type+"; "+self.Land,\
"</dd>"
これはウヰスキーのデータベースの定義であるが,データを定義しているのは前
半だけで,後半はテータの定義ではない.データの出力方法(函数)の定義である.
これに,
claymore=Uisge(
Name="Claymore",
Distill="Claymore",
Land="Scots",
)
cragganmore12=Uisge(
Name="Cragganmore",
Distill="Cragganmore",
Land="Scots",
Type="Single Malt",
Age="12",
)
royal_salute=Uisge(
Name="Royal Satute",
Distill="Chivas Bros.",
Land="Scots",
)
のようなデータを与へる.ここまでをuisge.pyとして,一つのファイルにしておく.
そして,下記のように,uisgeをimportしてやり,クラスuisgeのインスタンス
claymoreに対して,クラスで定義されたprintHTMLメソッド(函数)を演算子で結合してあげ
ると,
>>> import uisge
>>> uisge.claymore.printHTML()
<dt>Claymore</dt><dd>Claymore; Age: NaN; Blended; Scots </dd>
となる.これは,データをHTMLとして表現するためにフォーマットしなおした結
果である.それぞれのインスタンスに対して順番にメソッドを実行してやれば,
全てのデータのHTML用フォーマットが完成する.
このようにオブジェクトを使用することにより,データとメソッドを別々ではな
く,統一した形式で管理できるので,たいへん楽である.この例でオブジェクト
を使用しない場合は,データベースとそれを加工する函数を別途作成しなければ
いけない.この例は単純だから有難味が乏しいが,クラスの中にサブクラスをつ
くったり,クラスをまとめてひとつのスーパークラスにする(サブクラスと同じ
ことだが)時にクラスの真価が発揮される.データに対応したメソッドがデータ
と一緒についていってくれるのか,それとも別々に管理しなければいけないのか,
で管理コストは大きく異なる.
同じ言語を使っていると,その言語特有の世界観があたかも正しいもののように
自分の身についてしまいがちである.しかし,そのような考えは間違っている.
もし,比較言語学の対象に新たな言語に挑戦するというのであれば,JavaやC++
よりもLispやPrologのようなC言語由来ではない言語をお勧めする.その故は,C
言語由来の言語は,どれも同じような文法構造をしているので,あまり言語によ
る世界観の違いが浮き彫りになることはないためである.それでも,世界観の違
いはあって,たとえばperlとpythonは同じくC言語由来の兄弟関係にある言語
(perlが兄貴分)だが,コンテキストについての世界観がまるで逆なところ,自由
でmessyな構文とstrictで統一的な構文と,いろいろ世界観の違いが楽しめる.
しかし,しばしば,perl vs. python vs. ruby vs. PHP--のように,どれが優
れた言語か論争(意味のない論争をしばしばflameと呼ぶ)が勃発する.このよう
な言語論争は往々にしてbeliefの世界つまり宗教戦争になりがちである.一例と
して,goto文批判をあげる.Goto文は制御構文の一つで,ループ状構造から抜け
る際に行き先を明示して(to),そこに行って(go)もらう命令である.Goto文は,
しばしばコードの流れを乱し制御をあらぬところに飛すので,コードをこんがら
がったスパゲッティにしがちである.そこで「goto文はよくない,goto文を使わ
ないでおきませう」という運動が盛んになった.東大のProfesser Gotoが,「私
はいつもどこでもみんなに批判されるんですよ(笑)」とDon Knuthが書いていた
Knuth・有澤 (1994).ここにgoto文批判がbeliefの世界に属することが垣間見れる.
なぜかというと,science, logic and argumentの世界では,ものごとを述べる
のに理由付けreasoningが必要である.goto文批判は初期・提言者の意図とは違っ
て,いつでもどこでもgoto文を見れば無条件で「時代遅れだ,コードをわかって
いない」と批判し,そのgoto文がほんとうに必要なものかどうかは吟味しない.
ここにはreasoningはない(権威によるreasoningはあるかもしれないが)ので,
scietific argumentではなく,beliefの世界に属すると云える.言語論争はしば
しば上記のgoto文批判の様相を呈す.それは,よい/わるいと好き/嫌いと,ある
目的に適している/適していないの論点を混同しているためである.
-
Aho, A. V., B. W. Kernighan, and P. J. Weinberger (1989) <#2368#>The AWK
- Programing Language: Addison-Wesley. 邦訳 プログラミング言語AWK
足立高徳 凸版印刷(後 CMC出版が版 権を引継ぐ) 1989(2001), ISBN:4901280406.
-
アンク (2002)
- 『Cの絵本--C言語が好きになる9つの扉』,翔泳社,191頁.ISBN:
4798101036.
-
Arthur, Lowell Jay and Ted Burns (1997) Unix Shell Programming,
-
New York: John Willey and Sons, 4th edition, pp.518. ISBN: 0471168947,
邦訳: UNIX シェルプログラミグ, 伊藤・千吉良・西尾・宮下(訳), オーム社, 1993,
ISBN=4274077705.
-
Bentley, Jon Louis (1991) More Programming Pearls:
-
Addion-Wesley(Pearson Education). 邦訳 プログラマのうちあけ話
続・プログラム設計の着想.野下浩平・ 古郡延治 近代科学社 ISBN: 4764901773,
256p. 1991.
-
Bentley, Jon (2000) Programming Pearls,
- Boston:
Addion-Wesley(Pearson Education), 2nd edition, pp.239. ISBN: 0201657880,
1st ed in 1986, 邦訳 珠玉のプログラミング
本質を見抜いたアルゴリズムとデータ構造 小林 健一郎(訳)
ピアソンエデュケーション, 2000, ISBN: 4894712369, 308p.
-
Bowney, Allen, Jeffrey Elkner, and Chris Meyers (2002) <#2372#>How to think
- like a Computer Scientist--Learning with Python, Wellesley,
Massachusetts: Green Tea Press, pp.278. ISBN: 0971677506, on-line document
at http://www.thinkpyton.com/.
-
Browm, Martin C. (2002) Perl to Python Migration:
- Person
Education. PerlユーザーのためのPython移行ガイド,細谷 昭訳 2002,
ピアソンエデュケーション.
-
Dougherty, Dale and A. Robbins (1997) sed & awk programming:
-
O'Reilly, 2nd edition. ISBN: 1565922255, 邦訳 sed & awk
プログラミング(改訂版),福崎俊博(訳), 1997,ISBN:4900900583.
-
Eckel, Bruce (2001) <#2375#>Thinking in Python--Design patterns and
- problem-solving techniques: in editing. on-line document.
-
Flesch, R. (1976) The Art of Readable Writing,
- New York: Hungry
Minds.
-
深沢千尋 (1999) 『すぐわかるPerl Software Technology
- 16』,技術評論社.ISBN: 4774108170.
-
Gancarz, Mike (1995) The Unix Philosophy:
- Digital Press, pp.151.
ISBN: 1555581234, UNIXという考え方-その設計思想と哲学, 芳尾 桂(訳),
オーム社, ISBN=4274064069, 2001, 148p.
-
Gould, Alan・松葉素子(訳) (2001)
- 『Pythonで学ぶプログラム作法』,ピアソン・エデュケーション.ISBN:
4894714019,原題: Learn to program using Python: A tutorial for hobbyist,
self-strarters, and all who want to learn the art of computer programming.
-
Gunning, R. (1973) The Technique of Clear Writing,
- New York:
McGraw-Hill, revised edition.
-
原田賢一 (1986) 『Fortran77プログラミング』,サイエンス社.ISBN:
-
47819046110.
-
Hawley, David and Raina Hawley (2004) Excel Hacks:
- O'Reilly, pp.304.
ISBN: 059600625X, 邦訳 羽山 博・日向 あおい,320p, ISBN: 4873112052, 2004.
-
Kernighan, Brian W. and Rob Pike (1984) <#2378#>The Unix programming
- envirionment: Prentice-Hall, Inc. 邦訳 Unixプログラミング環境, 石田晴久(訳),
ASCII, 1985, ISBN: 4871483517.
-
Kernighan, Brian W. and Rob Pike (1999) <#2379#>The Practice of
- Programming-Simplicity, Clarity, and Generality: Addison-Wesley,
pp.267. 福崎 俊博訳 プログラミング作法 2000 ASCII ISBN:4756136494.
-
Kernighan, Brian W. and P. J. Plauger (1974) <#2380#>The Elements of
- Programming Style: Bell Telephone Laboratories, 2nd edition. 木村 泉訳
プログラミング書法 共立出版 ISBN: 4320020855.
-
Kernighan, Brian and Dennis Ritchie (1988) <#2381#>The C programming
- langrage, New Jersey: Prentice Hall, 2nd edition, pp.274. 邦訳
プログラミング言語C 第二版ANSI規格準拠 共立出版.
-
Kernighan, Brian W.・P. J.Plauger・木村泉(訳) (1981)
- 『ソフトウェア作法』,共立出版.ISBN: 4320021428,原題 Software Tools, Bell
Telephone Laboratories, 1976,.
-
Knuth, Donald E.・有澤誠(訳) (1994) 『文芸的プログラミング』,ASCII.ISBN:
-
4756101909,原題: Literate Programming 1991.
-
Lutz, Mark (1996) Programming Python:
- O'Reilly, pp.881.
新版および邦訳あり.
-
Lutz, Mark and Davia Ascher (1998) Learning Python:
- O'Reilly.
初めてのPython 紀太 章訳 2000 オライリー.
-
Mannuals, Creating Technical (1984) <#2264#>Cohen,
- G. and Cunningham, D. H.,
New York: McGraw-Hill.
-
Mertz, David (2003) Text processing in Python,
- Boston:
Addison-Wesley. ISBN: 0321112547.
-
椋田 實 (1993) 『はじめてのC [ANSI C対応] Software Technology
- 2』,技術評論社,第3版,343頁.ISBN: 4874085466.
-
Pilgrim, Mark (2004) Dive into Python:
- on-line document, pp.322. at
http://diveintopython.org/.
-
Raymond, Eris S. (2003) The Art of UNIX Programming:
-
Addison-Wesley.
-
Raymond, Eric S. (2005) ``How To Become A Hacker (Revision 1.
- 31)'',
url= http: //www.catb.org/ ~esr/faqs/
hacker-howto.html, p. 0. 邦訳: url= http://cruel.org/freeware/hacker.html.
-
Schwartz, Randal L. and Tom Christiansen (1997) <#2297#>Learning Perl (2nd
- ed): O'Reilly. 初めてのPerl 第二版 近藤嘉雪訳 (第三版もあり) 1998
オライリー.
-
砂原秀樹・石井秀治・植原啓介・林 周志 (1996) 『プロフェッショナル
- シェルプログラミング』,ASCII.
-
砂原秀樹・石井秀治・植原啓介・林 周志 (2001) 『プロフェッショナル BSD
- (改訂版)』,ASCII.
-
Sussman, Julie (1998) <#2309#>Structure and interpretation of computer
- programs, instructor's manual to accompany, Cambridge: MIT Press, 2nd
edition. ISBN: 0262692201.
-
高林 哲・鵜飼文敏・佐藤祐介・浜地慎一郎・首藤一幸 (2006) 『Binary Hacks
- ハッカー秘伝のテクニック100選』,O'Reilly,412頁.ISBN: 4873112885.
-
Wall, Larry, Tom Christiansen, and Jon Orwant (2000) <#2319#>Programming
- Perl: O'Reilly, 3rd edition, pp.1067. ISBN: 0596000278, 邦訳
プログラミングPerl Vol.1,2 近藤嘉雪訳,ISBN: 4873110963,4873110971.
-
Warren, Henry S. (2006) Hackers' Delight:
- Addison-Wesley Pub.,
pp.368. ISBN: 0201914654, 邦訳 ハッカーのたのしみ
本物のプログラマはいかにして問題を解くか.滝沢 徹他訳.SliB Access.ISBN:
443404683.
-
山本和彦 (2000)
- 『リスト遊び--Emacsで学ぶLispの世界』,ASCII,122頁.ISBN:
4756134424.
-
矢沢久雄・日経ソフトウェア(監修) (2001)
- 『プログラムはなぜ動くのか』,日経BP社,294頁.ISBN: 4822281019,How
program works.
-
吉田洋一 (1955) 『零の発見』,岩波新書.
-
結城 浩 (1995) 『ANSI対応 C言語プログラミングレッスン
- 文法編』,ソフトバンク,第2版.ISBN: 4890527559.
-
結城 浩 (1998) 『ANSI対応 C言語プログラミングレッスン
- 入門編』,ソフトバンク,第2版.ISBN: 4797307579.
-
結城 浩 (1999a) 『Java言語プログラミングレッスン
- (上)Java言語を始めよう』,ソフトバンク.ISBN: 4797308036.
-
結城 浩 (1999b)
- 『Java言語プログラミングレッスン(下)オブジェクト指向を始めよう』,ソフトバンク.ISBN: 4797310103.
-
斎藤 靖・小山裕司・前田 薫・布施有人 (1996) 『新Perlの国へようこそ
- Perl5対応版』,Computer Todyライブラリ34,サイエンス社,348頁.ISBN:
4781907954.
Pythonで学ぶデーダ処理の初歩 (2008-01-08 版)
この文書はLaTeX2HTML 翻訳プログラム Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds,
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
を日本語化したもの(
2002-2-1 (1.70) JA patch-2.0 版)
Copyright © 1998, 1999,
Kenshi Muto,
Debian Project.
Copyright © 2001, 2002,
Shige TAKENO,
Niigata Inst.Tech.
を用いて生成されました。
コマンド行は以下の通りでした。:
latex2html -local_icons -accent_images textrm -split 0 -noaddress web.
翻訳は tuzino によって 平成20年1月8日 に実行されました。
- ...
表計算ソフトである1.1
- 組織化しているビジネスはたいてい自前のツール
をもっている.
- ...EOT文字(符号) 1.2
- EOTはEnd
of Transitionの略で「これでメッセージおわり」という意味である.似た言葉
に,EOF(End of File: これでファイルはおわり),EOD(End of Data: これでデー
タ終わり)があるが,どれも同じ文字符号(ASCIIなら4)である.
- ...
./''が必要である.また,スクリプトをどの処理系1.3
- Shell,
Perl, Python, Rubyといろいろな処理系がある.デフォルトではsh(B Shell)で
ある
- ...車輪を二回発明してはいけない2.1
- とはいっても,自分でちょっ
と考へれば作文できるものはその都度発明すればよい.たとえば,ネット上には
本稿で後で紹介するデータの間引きプログラムのやうな簡単なプログラムは滅多
に置いていない.それはなぜか?そのような簡単なプログラムはC言語であれ,
awkであれ,perlであれ入門書を読めば誰でも作文できてしまうことだからだ.
ブロガーはともかくプログラマーはそのような簡単なプログラムを公開すること
をよしとしない.せいぜいか本稿のような言語の入門書の例題として紹介してい
るくらいである.置いておくのが悪いと主張しているのではない,念のため申し
添える.
- ...
検査段階で停止する言語もある2.2
- このような厳密な型の作法を強い型付
け(Strong Typing)と呼ぶことがある.C言語は弱い型付けで,C言語の人は,そ
れが普通ともっているのでStrong Typingは強い打鍵のことだと思っている.
Pythonは強い型付けである
- ...
使用するのは,10秒に1回でいいということがある2.3
- では,なぜ10秒に
1回サンプリングすることにしないのか,とふ疑問があるかもしれないが,最大
限取れるデータは取りたいのが科学者の質であるし,他の測定との同期や兼ね合
いで,解析に必要な精度以上細かく観測する必要があることがある.
- ...とし,間を180分割した温度である2.4
- もともとのFahrenheitの
発想は人間の標準体温を100度,当時人工的に作り出せる最低温度(氷に食塩を掛
けてエントロピー増加により熱を奪ったもの-17.8
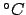 )を零度とする温度
系であったが,精度の問題で微妙にずれてしまった.現在の華氏では華氏100度
は摂氏40度である.摂氏40度は標準体温とは云へない.
)を零度とする温度
系であったが,精度の問題で微妙にずれてしまった.現在の華氏では華氏100度
は摂氏40度である.摂氏40度は標準体温とは云へない.
- ...時間はやっかいだ2.5
- 旧暦(太陰暦)と新暦(太陽暦)の違い.ユリウス歴と
グレゴリウス歴の換算など,時間はとてもやっかいだ.これらは本稿では取り扱
わない.
- ...
算機で処理させるには...頭いたくなってきた2.6
- これを簡単に決める
には,まづ,その年が400で割り切れるかどうか見る.割り切れる(2000年など)
なら,閏年である.割り切れない場合,100の倍数であれば閏年ではない.100の
倍数でなくて,4の倍数であれば,閏年である.
- ...
の形式変換を自分たちの手で実装しよう2.7
- 使える道具があるのだから,
わざわざ作らず,既存のツールを使うのは常道ではあるが,今のご時世,たいて
いのツールは揃っているのだから,既存ツールの再利用の論理を押し進めていく
と,たいていのものは自分で作らなくてもよくて,人のを使いまわせばよいこと
になる.しかし,いつかは誰も作ったことのないものが必要になる.その時に,
全て既存のツールを使っていた者は,いきなり高い壁の前に立たされる.
- ... filteringで対応する2.8
- TEXのコードを取り除くスクリプトも凝らなければたいした作文で
はないので本文を書き足すことがあれば,取りあげたい.